
Share this page





Create and configure pipelines
Pipelines represent the flow of your CI server jobs and steps. Use pipelines to get a clear, multi-level, analytic view of your pipeline runs and their status. This helps monitor quality and progress, quickly identifying and fixing issues as they occur.
Add a pipeline
When connected to a CI server, you can create a pipeline. Using the specified root job, a pipeline is built that represents the job flow starting from that root job.
The result of a pipeline run is determined by the result of its root job. Therefore, for the pipeline run result to reflect the results of other jobs in the flow, make sure that on your CI server, the results of those jobs are aggregated up to the root job.
To learn more about pipelines before creating them, see Pipelines.
Note: If you are working with Jenkins: You can similarly create and configure pipelines using the Application Automation Tools plugin on the Jenkins CI server. For details, see the section on creating and configuring pipelines on the Application Automation Tools wiki page.
To add a pipeline:
-
Prerequisites:
-
Make sure the Application Automation Tools plugin is installed on the CI server. For details, see CI server integration.
-
Make sure at least one CI server has been added in the Settings area. For details, see Add CI/CD servers.
-
-
In the Pipelines module, open the Manage tab.
-
Click the Add Pipeline button
 to add a pipeline.
to add a pipeline. -
Select a CI server. The list displays the servers created on the CI Servers settings page of the current workspace. For Azure DevOps integrations, see Run Azure DevOps pipelines.
-
Select the root job from which you want to start the pipeline. The list displays the jobs defined on the CI server you selected. If the communication with the server fails, the list is not available.
-
Enter a name for the pipeline and, optionally, assign the pipeline to a program and/or a release. If you select a release, you can also select a milestone.
-
The program, release, and milestone are automatically assigned to all test runs collected from this pipeline. If you change the program, release, or milestone, a new set of automated runs is created to represent all the tests running in the pipeline. This lets you view test results in the context of program, release, and milestone, and track their quality over time using the Dashboard widgets.
-
For details on programs, see Working with programs in pipelines.
-
Before selecting the release and milestone, we recommend you read the section Best practice: Link a pipeline to release and milestone.
Tip: If you assign the pipeline to the Default Release, the pipeline is always associated with whichever release is currently set as the default release.
-
-
Specify the pipeline's type. Select one or more types from the list: build, test, integration, deploy, security.
- Most types are optional. This definition helps you remember the lifecycle stages that this pipeline handles.
- You must select security if you want this pipeline's runs to show security vulnerabilities discovered by Fortify or SonarQube.
-
Set up notifications (optional). You can send emails to relevant users when builds or automated test runs fail.
- Notify committers upon run failure. Notify people whose commits were included in a pipeline run that failed.
- Notify test owners if their tests fail. Notify people who are owners of failed automated tests.
You can edit these options later in the pipeline's Details tab.
For more details, see Track commits associated with a pipeline run.
-
Set custom purge policy (optional). A global runs purge policy is set at the space level. To set a special policy for the pipeline, select Override space purging policy. If applicable, select the desired policy type and set a value.
The information is retrieved from the CI server and the pipeline is created. To edit the pipeline's name or release, click the Edit button  .
.
After the pipeline runs, you can see a comprehensive overview of the run results. For details, see Run pipelines.

Best practice: Link a pipeline to release and milestone
When creating a pipeline, you have the option of linking the pipeline to a release and milestone. When you link a pipeline to a release/milestone or modify the release/milestone value, all the future runs reported in the context of the pipeline are assigned to the selected release.
The following are recommendations for different scenarios.
| Scenario | Recommendation |
|---|---|
|
Continuous integration pipeline:
|
|
| Feature/story branching |
The CI on these branches would typically not be injected and should not have a release/milestone. |
| Automated regression cycle | When your release and milestone represent a release and cycle, it is recommended that you link the pipeline to both release and milestone to track results easily. |
Consequences of changing a release or milestone
When you change the Release or Milestone fields for a pipeline, you should be aware of the following significant consequences:
-
A new set of automated runs is created to represent all the tests running in the pipeline.
-
Failure analysis features are based on the history of a single automated run. As a result, when a new automated run is created the accuracy of the failure analysis insights is reduced until relevant history on the new run is built up.
Use parameter sets
Note: The following is supported in Jenkins, TeamCity, Bamboo, and GitLab.
If your CI server job is parameterized, you can define different sets of parameter values that can be used when running the pipeline job. Each pipeline can have multiple sets of parameter values.
For example, suppose that you sometimes run a job on one deployed environment, and other times on another. You can create one data set (Set 1) using the default URL and port, and another (Set 2) with a different URL and port. You can then run the pipeline a few times using different settings.
To configure parameters in a pipeline:
- Prerequisite: You must have the Manage parameters permission.
-
When creating a pipeline, if its job is parameterized, a table appears showing the parameters configured in the CI server, with their default values.
Note: In GitLab, by default only project-level variables are shown. To also see group or instance variables, modify the gitlab.variables.pipeline.usage property as described in GitLab service.
-
In the column headings, add columns to define additional sets of parameter values.
-
You can rename each column heading as needed.
-
You can edit parameter values in each set of parameters as needed.
Values are limited to 4000 characters, and each set name must be unique.
-
To clone a column, delete it, or reset to its default values, select the relevant menu item in the column.
-
Click Save.
When you run the pipeline, a dialog appears enabling you to choose which parameter values to use in the run. For details, see Trigger a pipeline run (optional).
-
If you change the job's parameters on the CI server, click Sync with CI on the pipeline's Details pane to get the latest parameters defined on the CI server.
Note: Only boolean and string parameters are supported. Invalid types are not displayed.
Customize your pipeline display
If you have a large number of pipelines defined, it may be helpful to show less information using filters.
In the Pipelines module, open the Analysis tab and use the toolbar to perform the following actions.
| Action | Description |
|---|---|
| Filter the list of pipelines to display only the ones you want to work with. |
Click the Filter pipelines button If you select a release or milestone in the summary bar, its pipelines are displayed in the main pain. Select the pipelines you want to display. If a filter is active, an identification dot appears on the filter icon. |
| Display less information about each pipeline in the list. |
Click the Show more/less info in pipelines button |
 and select the pipelines to display.
and select the pipelines to display. to show more or less information about pipelines in the list itself.
to show more or less information about pipelines in the list itself.Your selection is retained for future sessions.
Tip: Select pipelines for your pipeline run, and configure the run by applying filters and widgets. You can then save the configuration as a Favorite for your pipeline run. Access this configuration by choosing the saved favorite from the Favorites drop down. This allows you to apply the configuration to new pipelines without having to reconfigure the filters and widgets.
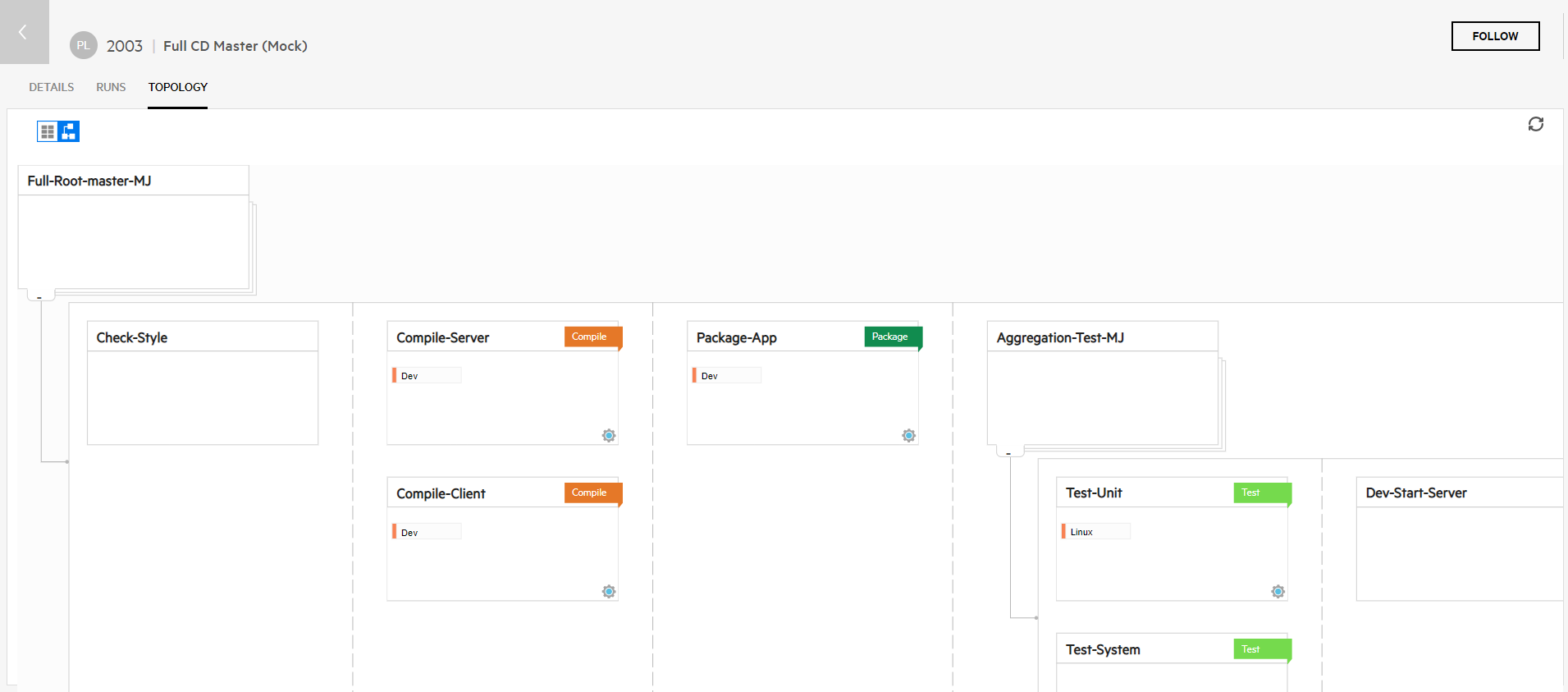
Explore a pipeline's graphical representation
When you create a pipeline, a graphical representation of the pipeline steps is created, starting from the root job of the pipeline.
If you are working with Jenkins, Bamboo, or GoCD, you can see the flow of the steps, including which steps run in sequence and which steps run as parts of other steps.
In the Pipelines module, open the Analysis tab and select a pipeline in the summary bar. Click the Menu button  and click View. Select the pipeline's Topology tab.
and click View. Select the pipeline's Topology tab.
Jenkins example:
Note: The pipeline is initially built based on the structure discovered on the CI server. When the pipeline runs on the CI server, any additional steps discovered during the run are added. You can see these steps the next time that you open the pipeline.
Here are visual clues for understanding and working with the display as you explore the pipeline in the Topology tab.
| Visual clue | Description |
|---|---|

|
The pipeline's ID and name. |

|
Click to view the pipeline in a Flat view or Tree view. Tree view. Displays the hierarchy and flow of the pipeline. Flat view. Displays the pipeline steps side by side without describing the hierarchy or flow. This view is useful for gaining an overview of complex pipelines. In this view, you can also filter pipeline steps. For details, see Filter pipeline steps . |
| <Step name> |
A step in the pipeline. Click the step's name to open the job on the CI server. For example:
|
  |
For a pipeline that displays hierarchy, click to expand and collapse the steps that run as part of their parent step. (inner jobs) |
|
Steps on the same side of a dotted line run in parallel to each other. (parallel jobs) Steps on the right side of a dotted line run after the steps on its left side end. (sequential jobs) |

|
Steps that run as part of the pipeline. In a pipeline that displays hierarchy, the steps after this arrow run only after the calling step and its children end. (sequential jobs) |
| <Step type> |
Click to label the step type. You can select the following step type labels: Compile, Package, Deploy, Security, or Test. For example:
|
  |
Click to configure step information, which is added to the pipeline step as a tag. You can use tags later, for example, for filtering test run results. You can specify:
For details, see Define test and test run information. |

|
Redraws the topology based on the current pipeline steps defined on your CI server. This is useful, for example, if you changed the pipeline flow on the CI server a few times and the pipeline structure includes steps that no longer belong in the flow. When redrawing, an attempt is made to maintain the pipeline step configuration. However, for steps that moved significantly, the configuration may be lost. |



Label pipeline steps by job type
Enhance the pipeline's usability by labeling steps. This makes it easier to understand the purpose of the steps and provides contextual information for test run results.
To label pipeline steps:
-
In the Pipelines module, open the Analysis tab and select a pipeline in the summary bar. Click the Menu button
, and select View. -
Select the pipeline's Topology tab.
-
Click the step label, and select a job type for the step. The label helps you understand the pipeline flow. In the flat pipeline view, you can also filter the pipeline to show only steps with specific labels.
Job types include: Compile, Package, Deploy, Test, and Security.
When the pipeline runs, the labels are added to the resulting builds. When analyzing pipeline run results in the Builds tab, the labels help you understand the context of the builds.
Ignore or hide results of specific steps
Your pipeline may include steps or tests whose results you do not want to track. You can ignore such steps or hide their results from the quality analysis.
-
In a pipeline's Topology tab, click the step's Configuration button
. -
Select one of the following options.
Option Description Ignore this step and the ones that follow it
Configure pipelines to ignore the status, duration, and test results of certain steps and those that follow them.
For example, a pipeline might include post-build or downstream steps that you do not need to track. If these steps are ignored, the pipeline run status and duration is updated without waiting for them to finish running.
Hide failed builds when analyzing build failures Sometimes, the failure of a specific step's build is not interesting when analyzing pipeline run failures. For example, a parent step's failure is not interesting if it indicates only that the child step failed.
Configure the pipeline step so its build failures are not included in the pipeline's Overview and Builds tabs. This helps focus on the failures that matter.
To hide build failures resulting from specific steps:
-
In the pipeline's Topology tab, click the step's Configuration button
, and select Hide failed builds when analyzing build failures. -
In the pipeline run's Builds tab, right-click a build that you want to hide, and select Hide builds from this pipeline step.
To unhide a step's build failures:
-
In the pipeline's Topology tab, click the step's Configuration button
, and clear the Hide failed builds when analyzing build failures option.
Ignore test run results If a step runs tests that you do not want to track, select Ignore test run results. When this step runs tests, the results are not sent, and the corresponding tests are not created.
For example, we recommend that you use this option to ignore unit tests. This prevents unnecessary load on your server, which could result in performance issues.
Specify whether to delete test run results that were previously collected from this step. If all of a test's run results are subsequently deleted, the automated test is deleted as well.
Caution: Deleting test results affects your pipeline's build run history. In addition, failure analysis is not available for steps whose test results are ignored.
-
-
The pipeline step reflects the selected option in the pipeline's Topology tab.
For example:

Define test and test run information
For pipeline steps that run tests, add environment tags and testing information for the step.
-
Test Fields and Testing Environments. This adds tags to your pipeline step. When this pipeline step runs tests, its tags are added to the tests, test runs, and builds. You can then filter builds and test run results according to these tags, and enhance your product and release quality analysis.
Example: This Jenkins step, QA-Functional-Chrome, is labeled as a Test and has the following tags configured:
-
Test fields: Framework = TestNG, Test type = End to End, Test level = Integration Testing, Testing tool: Selenium.
-
Testing Environment: WinServer2012 (OS), MSSQL (DB), QA (AUT Env), Chrome (Browser).

-
-
Build Report and Test Run Report. If your build creates reports, you can add a link to the report in the relevant automated test runs. This report can be stored on your CI server or elsewhere, and may help analyze test run failures.
Configure a URL or URL template for report links in your pipeline step. A link is added to the test runs that are created as part of this pipeline step and to the build that is the result of this step.
To configure a pipeline step:
-
In the Pipelines module, open the Analysis tab and select a pipeline in the summary bar. Click the Menu button
and select View. 
-
Select the pipeline's Topology tab.
-
Click the Flat view button
 , and click the step's Configuration button .
, and click the step's Configuration button . -
In the Test Fields tab, add information about the type of tests the step runs, and the tools and framework it uses to run them.
Select from the predefined values.
Field Possible values Framework Select from the list. Example: JUnit, TestNG, OpenText Functional Testing. Test type One of: Acceptance, End to End, Regression, Sanity, Security, Performance.
Testing tool
Select from the list. Example: Manual Runner, Selenium, OpenText Functional Testing, OpenText Functional Testing for Developers, OpenText Core Performance Engineering, LoadRunner.
Test level Select from the list. Example: Integration Test, System Test, Unit Test. You can add values to the Framework and Testing tool lists. To do this, add tags to the pipeline step using the API, or the Jenkins plugin UI.
The following fields are automatically set for test runs discovered on Jenkins pipelines.
Field Set for test results from Testing tool
OpenText Functional Testing
LoadRunner
OpenText Core Performance Engineering
LoadRunner Enterprise
Framework OpenText Functional Testing Test type LoadRunner Enterprise If you manually added tags to the pipeline step that runs these test, your tags override the automatic ones.
-
In the Testing Environment tab, choose environment tags for the pipeline step, such as an operating system, browser, and database.
Environment tags are grouped by category with a default list of environment tags. Admins and leaders can also define new environments tags, based on the project developing model. For details, see Environment tags.
Do one of the following.
Goal Action Use an existing environment tag -
Expand the Environment tags field and select the relevant environment tags.
-
Type in the box to search for a specific value.
Add a custom environment tag -
Expand the Environment tags field, and type the name for the new environment tag.
- Select the new tag name and then click on it.
-
In the Add Environment Tag box, select an existing category, or add a new category by typing in a name for the new category, and double-clicking the new value.
Example:
-
Add a Lab Machine category with tags for each machine you use for nightly runs.
-
Add environment tags for specific browser versions or development branches.
Create conditions for setting environment tags during the build run, based on build parameter values
-
In the table, add a row for each environment tag you want to assign dynamically.
-
In each row, specify:
Parameter name + value ==> Environment tag
-
Select the build parameter name from the list of build parameters available for this step.
Note:
-
If you use the Matrix plugin on Jenkins, the pipeline displays child steps, generated during the build run. Each one represents a set of build parameter values.
-
Conditional environment tags are applied to parent steps. These are applied to the generated child steps. You cannot modify a child's configuration.
-
-
-
In the Report Customization tab's Build Report URL field, enter a URL or a URL template to use for creating a link to reports generated for your builds.
If you include {job_name} and {build_number} placeholders in the template, the actual job name and build number are used in the URL when creating the link.
Copy codeExample:http://myServer:myPort/jenkins/job/{JobName}/{BuildNum}/reports/logs/jenkins-test-reports.htmlThe links are added to the test runs that are created as part of this pipeline step and to the resulting build.
-
In the Report Customization tab > Test Run Report URL field, enter a URL or a URL template that can be used to create a link to reports generated for your test runs.
Note: If you have defined an External Report URL in your CI server, that URL setting overrides the OpenText Core Software Delivery Platform URL definition.
If you include placeholders in the template such as {test_class} and {test_name}, the actual test class and name are used in the URL when creating the link.
Copy codeExample:http://myServer:myPort/{root_job_name}/{job_name}/{build_number}/{test_component}/{test_package}/{test_class}/{test_name}/{root_job_build_number}/reports/logs/jenkins-test-reports.htmlThe links are added to the test runs that are created as part of this pipeline step.
Tip: You can select the checkbox Override test run report URL inheritance so that the current job does not inherit the URL format from its parent in the topology.

Filter pipeline steps
Filter a pipeline by its label or job name to display only pipeline steps with a certain label and/or steps with a specific string in their name.
If you set up a filter on a specific pipeline, that filter is used again the next time you view the pipeline.
To filter pipeline steps:
-
In the Pipelines module, open the Analysis tab and select a pipeline in the summary bar. Click the Menu button
and select View. -
Select the pipeline's Topology tab.
-
Click the Flat view button
, and filter the pipeline steps using one of the following.Filter option Description Filter by label Select from the Labels to specify the type of pipeline steps you want to see.
Filter by job name Click the Search button
 and type in the context search box to see only steps whose name contains the specified string.
and type in the context search box to see only steps whose name contains the specified string.Note: If you filter by label and by job name, the pipeline displays only steps that match both filters.
Delete a pipeline
In the Pipelines > Analysis page, click the Menu button on a pipeline, and then select View.
When the pipeline's details appear, click Delete and confirm the action.
If you delete a pipeline:
-
All of the pipeline's labels and configuration information are lost.
-
The pipeline runs and the automated test runs from this pipeline are deleted. The automated test entities remain.
Special pipeline types
The following section describes how to work with particular types of pipelines.
Pipeline stages are shown in the pipeline topology. Tests and commits are linked to the root jobs, as they are in Jenkins. Note that you cannot add tags to stages because tests are linked to the root job.
If you are working with supported multi-branch pipelines, a corresponding child pipeline is automatically created whenever a new branch is built for the first time (after the parent pipeline was created). You can use the pipeline's menu commands to filter which branches to show.
For example, suppose you have a pipeline for your master branch, and you create a branch off the master in Git and run tests on a custom branch. In this case, a branch pipeline is automatically added to the master pipeline, and shows your tests on the branch pipeline. If you merge your branch and delete it, the related pipeline is automatically deleted.
Multi-branch is supported as follows:
-
Jenkins plugin from version 5.7, based on Multi-branch pipeline job.
-
Bamboo plugin from version 1.9.6, based on plans with branches.
-
GitLab plugin from version 1.1.45, based on repository with branches.
-
Azure DevOps extension.
Note: If you create a pipeline without branches, and then add branches in GitLab, OpenText Core Software Delivery Platform does not reflect this change. In this case, delete the original pipeline and create a new one for the multi-branch plan.
Builds of jobs triggered directly are recognized. If you have a root job triggering multiple child jobs downstream, and you want to track each child job as a pipeline, see https://portal.microfocus.com/s/article/KM000026949.
 Next steps:
Next steps:



