
Share this page





Type mapping
This topic describes type mapping and how to define mappings between a connection's data sources.
About types
A type is a system asset such as an epic, issue, requirement, task, or user story. When creating a connection, you must add at least one type to synchronize between your master and target data sources. For example, you may want to map a Broadcom Rally Central hierarchical requirement to a story.
The types that are available to add to a connection are limited to the types that you added to your data source. If the type that you want is not listed, return to the Data Sources tab and add the type to the data source. For details, see Create a data source.
Several types of mappings between masters and targets are available: one-to-one, many-to-one, and one-to-many.
If you mapped two select-list fields, you need to make sure that the fields' values are also mapped. For details, see Value maps.
Note: If you save the connection before adding any types, you can edit it later and specify the types. If you do not save the connection before pressing Next (to go to the Types and Fields page), a preselected list of types and fields is mapped automatically.
Default direction
In the connection wizard, you specify a default direction for synchronization. This setting is inherited by all child levels (type, field) unless explicitly overridden. When a child level inherits this setting from its parent, the Direction shown is Inherit with gray text or a gray arrow.
The direction specified at the type-mapping level is used when creating a new field mapping. The direction specified for field mappings is used when you update a mapping.
The following example demonstrates a combination of direction settings, both inherited and explicit:
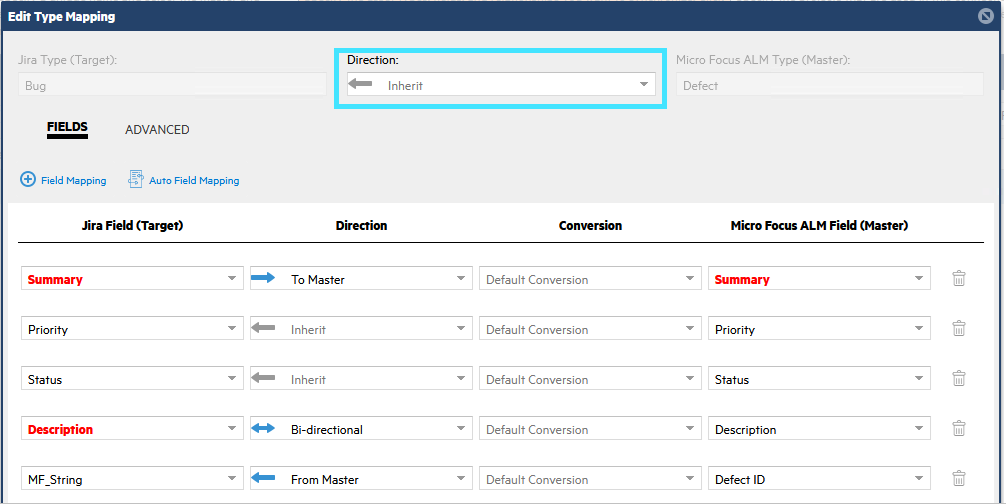

Type and user maps
Before you run a synchronization, you must map fields between the data sources. Mappings in a connection are per project.
Type maps are the most convenient, and usually the most logical way to indicate corresponding fields between a master and target. The type in one data source synchronizes to an equivalent type in the other. For example, ALM Octane defects synchronize with Azure DevOps bugs. For complex use cases, you can choose to map completely different types across products, as long as the resulting data satisfies the product's workflow and integrity. The master and target type mapping can be uni-directional or bi-directional.
User maps are user representations that map user properties across endpoints. You can manually construct maps with the user interface. User maps are ideal if you have different representations across endpoints. For example, when mapping between ALM Octane and Jira, the Jira assignee field needs to be mapped to the ALM Octane owner field. For details, see User maps and user matching.
The following are some common user representations for the user Joe DiMaggio:
- Jira DisplayName: Joe DiMaggio
- ALM Octane email, full_name, or name: JDiMaggio@opentext.com
- ALM/QC loginname: joedimaggio
- Azure DevOps DisplayName: Joe DiMaggio
Use the DataSourceUsers and UserMaps batch scripts to to automate the process of storing mapped user representations from different systems into the database. For details, see DataSourceUsers and UserMaps scripts.
Define type mappings
You define type mapping in the connection wizard, as a step in creating a connection, or later when editing a connection.
To define type mapping in a connection:
- In the connection wizard, click Next to go to the Types and Field tab.
-
In the Default Sync Direction list, select a direction for data synchronization. Synchronization between all types and fields will be performed in this direction. You can override this setting for specific types. Possible values for synchronization direction are:
Direction Description From Master Data is only synchronized from the master to the target. To Master Data is only synchronized to the master from the target.Bi-Directional Data is synchronized both to and from the master and target. (This is the default.) Note: When mapping to or from a read-only field, select the direction prior to selecting the non read-only field name on the other endpoint.
-
You can allow the wizard to automatically map the data sources' types and fields. Click Auto Type Mapping. The wizard attempts to auto-replace and map all types exposed by the selected data sources, and their fields. If you choose Type one, the types that you see in the mapping are reset to the types that are available in the auto-map.
Caution: If you use auto type mapping, then mappings that you manually defined earlier may be overwritten.
To set the type and field mapping manually, click + Type Mapping. The Add Type Mapping window opens. For more details, see Map types manually.
Map types manually
If the connection's types cannot be mapped automatically, you can map them manually.
To add a manual type mapping:
- In the Types and Fields tab of the connection wizard, click + Type Mapping. The Add Type Mapping dialog box opens.
- The Target Type and Master Type fields list all the types that you exposed in the target and master data sources. Select the types to map from the target and master data sources.
- In the Direction field, select a direction for data synchronization. Select the "Inherit" option to use the default direction that was set in the main Types and Fields tab. For details, see Define type mappings.
-
After selecting the types to map, you can now map the types' fields. Click Fields.
- To automatically map the types' fields, click Auto Type Mapping. The wizard attempts to map the fields between both types.
- To define a manual field mapping, click Add Field Mapping.
-
Select fields in the target and master data sources to map with each other.
For a list of the field types that can be mapped, see Define type mappings.
For details on mapping relationship fields, see Relationship mapping.
- Select the synchronization direction in the Direction list for each field. By default, the direction is inherited from the type mapping.
-
In the Conversion field, we recommend using Default Conversion.
Apply one of the following values only after careful consideration:
Default Conversion (Default) The field data is not altered when synchronizing.
Note: Prior to 25.1 this was called No Conversion.
Apply user map If neither side of the mapping is a user property, you can apply the user map by selecting this option. CSV conversion Available for: 25.1 and later
When converting from a multi-value field to a single value field, this conversion type packages all values into a string with values separated by commas.
When converting from a single value to a multi-value field, the conversion unpacks comma-separated value elements to a list of values.
For details, see Map multi-value to single-value fields.
Master is HTML If the master side of a field mapping contains HTML-formatted content and you want, or are allowed only, plain-text content in the target. This setting converts the HTML content in master to plain-text content in target. Target is HTML If the target side of a field mapping contains HTML-formatted content and you want, or are allowed only, plain-text content in the master. This setting converts the HTML content in target to plain-text content in master. - If the fields you are synchronizing use different values, create a value map. For more details, see Value maps.
- Click the OK button to save your mappings and close the Add Type Mapping dialog box.
Relationship mapping
In addition to mapping attribute fields between types, you can also map relationship fields.
A relationship field defines the link between two types in a data source. For example, in ALM Octane, a story is linked to a feature by the story's Feature field.
You can synchronize those relationships between data sources. For example you can map and synchronize the ALM Octane story-to-feature relationship with a similar story-to-epic relationship in Jira.
Considerations for relationship mapping
- The relationships in either data source may not be the same type. For example, ALM Octane's story-feature relationship is a parent–child relationship. Whereas most relationships in Jira are many–many relationships.
-
Where there is ambiguity between relationship and attribute fields, the relationship is represented as a field with the prefix link.
For example, in the list of Jira story fields, there is a fixVersions field. This is a regular attribute field that is populated in Jira by a plain string. The link.fixVersions field is added to represent the story's relationship to a virtual fixVersion entity. This allows you to treat Jira's fixVersions as an ALM Octane release.
Map children links
Mapping links (relationships) between items from one endpoint type to another are supported, provided that the item types are mapped. For example, to synchronize ALM/QC defect Release and Release Cycle links with Jira Release and Sprint links, you must map the Release to Release and the Release Cycle to Sprint types in that connection.
In most cases , the default behavior of this mapping updates or creates the desired fields. Make sure to consider the architectural differences of the endpoint types. For example, unlike ALM/QC, Jira sprints are not linked to Jira releases. In addition, unlike ALM/QC, in Jira, start and end dates are not mandatory fields.
If you do not want to synchronize the parent types, such as sprint, release, release cycles, and iterations, but you want to synchronize the links for child types, such as defects, bugs, or requirements, use one of the following methods:
Map by name
Map by name incorporates custom utilities to map ALM/QC to Jira, ALM to Azure DevOps, ALM Octane to Jira, ALM Octane to Azure DevOps, and ALM/QC to ALM/QC by name.
For this method, you must create the fields, such as sprints, releases, or release cycles on the endpoint systems, in the relevant projects. You must also make sure that the field names are identical, as they are case-sensitive.
These utilities run directly on the endpoint systems and perform the following steps:
-
Query the database and find the supported types in all projects in all of the running connections.
-
Match the entities of these types by name.
-
Retrieve the IDs and write them into the database as cross references.
These utilities can be integrated into a nightly purge script, so that they run when the Connect service is down. This serves as a scheduled catch-up for changes made to the matching artifacts. For information about the utilities, contact support.
Manually map
Manual mapping is an alternative method that the system configuration admin can deploy. With this strategy, names are not used.
The admin should:
-
Determine the matching values, for example the Jira Release that corresponds to the ALM/QC Release, and the Jira sprint that matches the ALM/Octane release cycle.
-
Import or insert the cross references as <adds> pairs directly into the database. For details, see Manage cross references.
Additional guidelines
To ensure the success of the above methods, synchronizing must be prevented while mapping the types. For example, your admin should only map the ALM/QC Release type to the Jira Release type, and the Release Cycle type to the Jira Sprint type, but explicitly exclude all of these types' properties.
This approach, mapping types without properties, allows the loading of cross references into memory from the database without creating or updating the artifacts on either side. This approach also allows control at the connection level.
An alternative approach is to set the type to ReadOnly at the data source level. This approach however, affects all connections associated with the data source.
Note: When mapping links using calculated values, you must use the FindFirst function to set a value.
For example, you cannot set a calculated value using this syntax:
set Release = 123456
Instead, use the following syntax:
set Release = FindFirst(Release) where ID equals 123456
For details, see Functions.
Value maps
If you mapped two select-list fields, you need to make sure that the fields' values are also mapped. A value map defines how a field value in Product A maps to a field value in Product B.
When mapping lists of values, the following guidelines apply:
- You can map the ALM Octane Phase to the ALM/QC Direct Cover Status.
- Each target entry must be mapped to an entry on the master.
- Unmapped entries trigger a synchronization failure on the artifact. For details, see FAQs.
The example below shows value mapping between an ALM Octane and ALM/QC project.
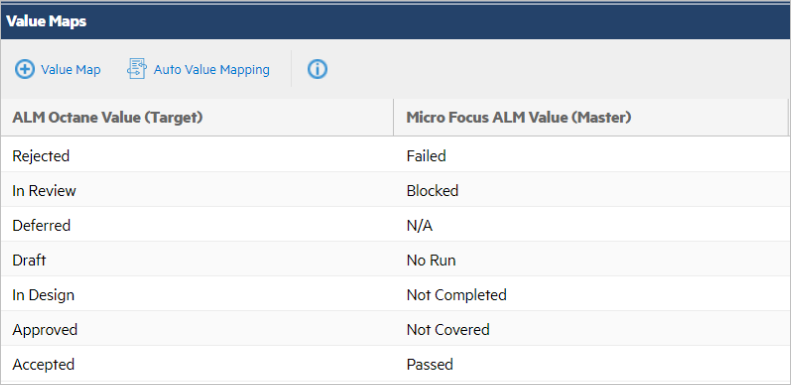
To define value maps:
- In the connection wizard's Types and Fields tab, expand a type mapping. The types' fields are listed.
- Click the Edit value map button
 . The Value Maps dialog box opens.
. The Value Maps dialog box opens. - Click Auto Value Mapping to allow the automatic mapping of the field values, or + Value Map to map the values manually.
- On each row, select a value in the master's field to map to the corresponding value in the target's field.
-
Select a value for the Default Target Value and Default Master Value from the dropdowns. These values will be used for any values that were not explicitly mapped.
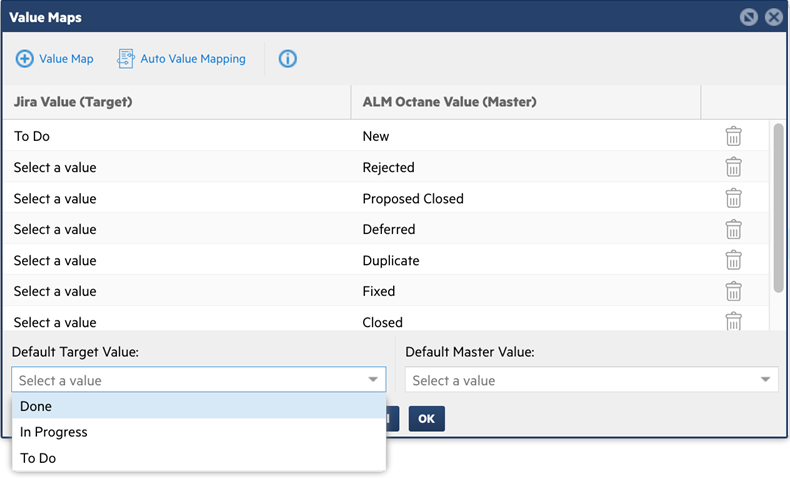
Note: It is possible that the field in Product A has more values than the equivalent field in Product B. In this case, you need to map more than one value in Product A to the same value in Product B.
Example:
| Product A | Product B |
|---|---|
| New | Open |
| In Progress | Open |
| Done | Closed |
The last value in Product A that is mapped to the same value in Product B appears in bold (see above). This indicates that, when changes are synchronized from Product B to Product A, the "Open" in Product B will translate to "In Progress" in Product A, and not to "New".
Supported type and field type mappings
When mapping Test entities between ALM/QC and ALM Octane, a uni-directional mapping from ALM/QC to ALM Octane is supported.
The following are the supported type mappings for Test entities, available in the Connection wizard's Types and Fields page:
| ALM/QC type - Master | ALM Octane type - Target |
|---|---|
| Release | Release |
| Run | Run Manual |
| Test | Test Manual |
| Test Instance | Test Suite Link To Test |
| Test Set | Test Suite |
The following are the suggested minimum field type mappings for the above types:
| Types: ALM/QC-ALM Octane |
Fields: ALM/QC - Master |
Fields: ALM Octane - Target |
|---|---|---|
| Release-Release |
End Date, Name, Start Date |
End date, Name, Start date |
| Run-Run Manual |
Attachment, Related Comments, Run Name, Run Steps, Status, Test Instance |
Attachments, Comments, Name, Run Steps, Native status, link.Test Suite Link To Test |
| Test-Test Manual | Attachment, Description, Design Steps, Status, Test Configuration, Test Name | Attachments, Description, Steps, Phase, Data Table, Name |
| Test Instance-Test Suite Link To Test | Test, Test Set | Test, Test Suite |
| Test Set-Test Suite | Description, Name | Description, Name |
For the ALM Octane Run Manual type, assign a calculated value for the Release.
To set the calculated value:
In the Connection wizard's Projects and Rules page, click the Edit Rule button  to edit the connection type rule.
to edit the connection type rule.
-
Click the Calculated Value (Target) tab.
-
Enter Release into the Set field box, and the release name in the To Value box.
The following table lists the supported field type mappings:
| Field type | Maps to types |
|---|---|
| datetime | datetime, richtext, string, date |
| boolean | boolean, richtext, string, enum |
| item | item, string |
| long | long, richtext, float, int, double, string, long |
| richtext | richtext, datetime, float, boolean, int, double, enum, date, string, user, long |
| float | float, richtext, int, double, string, long |
| int | int, richtext, float, double, string, long |
| double | double, richtext, float, int, double, string, long |
| attachment | attachment |
| comment |
comment Note: When performing a synchronization between mapped comment fields, the synchronization engine automatically adds a header to the comment in the other endpoint (for supported connectors). This comment header lists the user who added the comment and the date it was added. The header is delineated with the "===" characters. For example, for a synchronization between an ALM Octane user story and a Jira story, a comment was added to the ALM Octane user story: It will appear in the Jira comment, preceded by a header: “===” “Inserted by ...: John 10:00 AM [Z] 03/02/2023” “===” “Please review this story” Note: The following connectors can display the comment header: ALM Octane, Azure DevOps, Confluence Cloud, and Jira. The following connectors generate information that can be included in the comment header: ALM/QC, ALM Octane, Azure Dev Ops, Confluence Cloud, and Jira. |
| enum | enum, richtext, enum, string, boolean |
| date | date, richtext, datetime, date, string |
| string | string, richtext, datetime, float, boolean, int, double, enum, date, string, user, long |
| user | user, string, richtext |
string - date/time conversion
A string containing a datetime value should follow the syntax below:
"yyyy-MM-dd" + optional("'T'HH:mm:ss" + optional(".nnnnnnnnn")) + optional("+2:00" + optional('[Region/Zone]'))
Using this format, the string is converted to an ISO date/time format.
Map multiple types to a single type
When mapping two or more types from one endpoint to a single type endpoint, the receiving endpoint must be able to distinguish between the types in the syncsets.
For example, consider a case where a Jira Story and a custom type called "Jira Support" are both mapped to an ALM Octane story type. The Jira Support type is mapped uni-directionally to the ALM Octane story, while the Jira Story is mapped bi-directionally to the ALM Octane story.
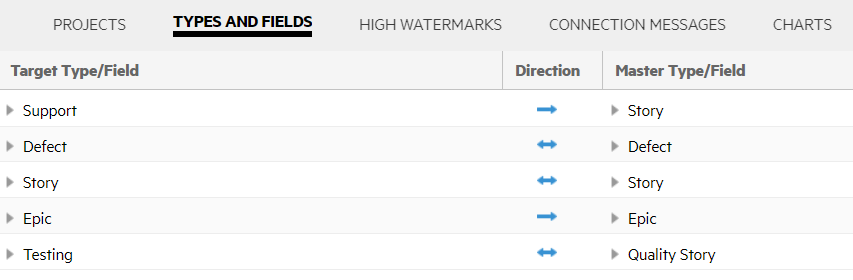
In this case, the receiving endpoint, ALM Octane, must be able to distinguish between stories syncing from the Jira Support type and stories syncing to/from the Jira Story type.
To enable the receiving endpoint to make this distinction:
- Add a custom field to the target endpoint type, the ALM Octane story. The field can be a Boolean type, for up to two cases, or a string/list for three or more type cases.
-
When mapping to the ALM Octane story, make sure that the Master Calculated Value is set to the correct value:
- False: for the Jira Support type
- True: for the Jira Story type
-
When reading the ALM Octane stories, set the Master Sync Criteria to accept only stories with the value set in the following way:
- False: for the Jira Support – Jira Story syncset
- True: for the Jira Story – Jira Story syncset
These steps ensure that only relevant ALM Octane stories are considered when processing each syncset, and the ALM Octane stories do not overlap across the two syncsets: the Jira Story–ALM Octane syncset and the Jira Support–ALM Octane story syncset.
Example: Uni-directional mapping between Jira epic and story to ALM requirement type
The following is a uni-directional mapping between Jira epic and story to requirement type in ALM. Jira epic is mapped as a requirement of type Folder, and Jira story is mapped as a requirement of type Business. The parent->parent-id mapping ensures the requirements are moved to the relevant folder. In order to successfully synchronize this multiple-types to single-type scenario, we need to ensure that each syncset only processes the relevant ALM requirements.
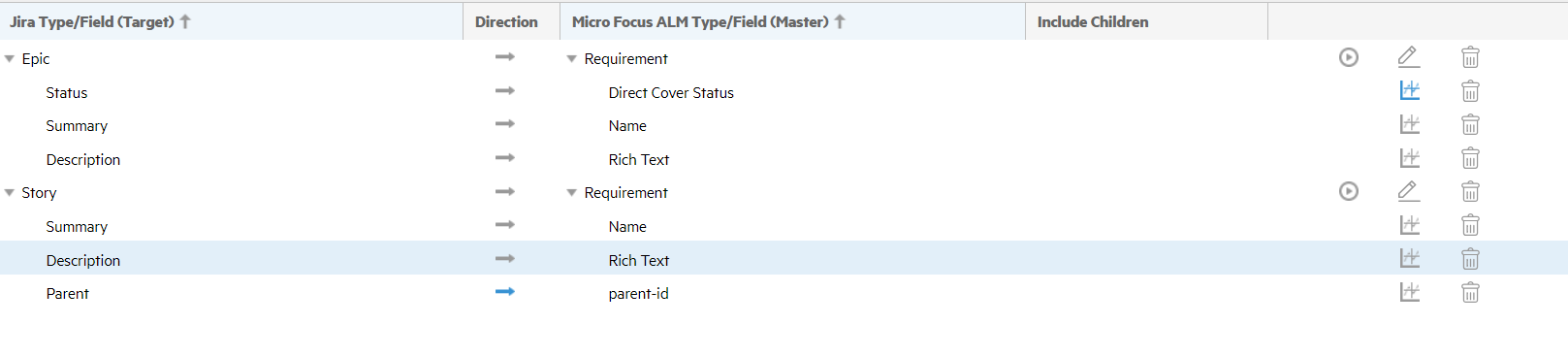
-
Set the Master calculated values for requirement type in epic->requirement to Folder.
-
Set the Master calculated values for requirement type in story->requirement to Business.
-
Set the Master Sync Criteria on the epic->requirement to only sync requirement type Folder.

-
Similarly, set the Master Sync Criteria on the story->requirement to only sync requirement type Business.

The above steps ensure that only relevant ALM requirements are considered when processing each syncset. The ALM requirements do not overlap across the two syncsets, namely the epic->requirement syncset and the Jira story–>requirement syncset.
Map multi-value to single-value fields
Available for: 25.1 and later
When mapping a multi-value field to a single-value field, you can use CSV conversion to merge multiple values into a single value, and to split a single value to multiple values. For details, see CSV conversion.
This conversion is only applicable when the single-value field is a string-like field, such as a string or rich text field.
Multi-value to string conversion
By default, when you map a multi-value field to a single-value field, only the first element of the multi-value field is used.
When you select CSV conversion, the conversion packages all of the values in the multi-value field into a string, with values separated by commas.
For example, [One,Two,Three] is converted to "One, Two, Three".
String to multi-value conversion
By default, when you map a single-value to a multi-value field, the conversion adds the value as a single element of a collection.
When you select CSV conversion, a comma-separated values element is unpacked as a list of values.
For example, "One,Two,Three" is converted to [One,Two,Three].
Additional type mapping guidelines
This section lists several guidelines that apply when mapping types.
- You can maintain relationships between types. In a connection, relationships are treated like fields in the type mapping. First you choose the relationship field in one product, and then choose the relationship in the other product.
- The connection wizard does not reflect changes in types. Therefore it does not convert a story to a defect or vice versa. Most products do not support changes in types. The wizard creates a parallel item of the new type, provided that the new type is configured in the connection.
- You can map any type, such as a story or defect in one product, to any type in another product.
- For any given type mapped for a connection, the required fields for that type are displayed in red. An error message indicates that the synchronization may fail if an artifact is being created on the type without the required field. You can ignore this warning if the synchronization direction is uni-directional, with data flowing out from the type whose fields are displayed in red. In this case, none of the required fields of the type should appear in the mapping, and the warning message can safely be ignored.
-
When mapping workflow statuses from one endpoint system to another, ensure that each system is able to transition from one status to all others. This is required for all projects being synchronized, but only for the data source user account. The data source user account must be able to execute any state transition that satisfies the corresponding state transition on the other endpoint. All endpoint users will continue to see only the relevant workflow state transitions. For example, consider a state transition of a defect in ALM Octane. The user moves the defect from New to Rejected, which is a permitted transition in ALM Octane. However, when the connection tries to synchronize the modified ALM Octane Defect to a Jira Bug, it fails since the transition from New to Rejected is not permitted in Jira. The Jira server will throw an exception stating that the transition is not supported and as a result the synchronization will fail. Connect only serves as an intermediary service, taking state transition data from one endpoint and applying it to another.
Map custom type fields
You cannot map a custom reference field to a custom list field from one endpoint to another. If you try to do so, you may receive an error message indicting: Target field is of type item and cannot be mapped to Master field of type enumeration.
For example, if you defined a custom Release type reference and Detected in Release fields in Jira, and in ALM/QC you also defined a Release type custom field, but Detected in Release as a list field, they will not be able to be mapped.
Although they are both Release type fields in their respective systems, the fields are both custom fields with different meta data types.
As a workaround, use a VB script to set the field in the other endpoint.
Follow these steps (based on the example above, with Jira and ALM/QC endpoints):
-
Map the Jira Detected in Release to a custom string field in ALM/QC. The custom string field should have the name of the Release.
-
Write a custom ALM/QC VB Script plugin that is triggered when the custom field is assigned a value.
-
Use the custom field's value to set or choose the corresponding entry in the custom list.
For assistance with creating VB Script plugins for ALM/QC, contact ALM/QC support.
Mapping examples
The following examples illustrate the connections and mappings for several typical use cases. For additional use cases, see the Help Center's Methodology menu.
The following example shows an ALM Octane and Jira connection that synchronizes five types:
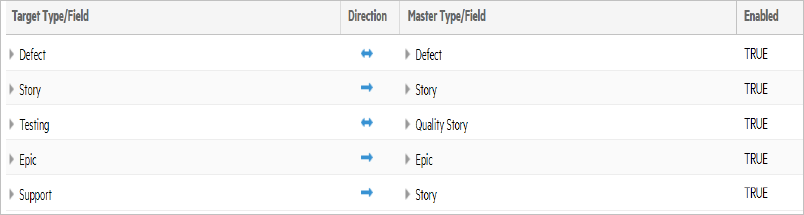
- A Jira defect synchronizes bi-directionally to an ALM Octane defect.
- A Jira epic synchronizes uni-directionally to the ALM Octane epic.
- Both Jira Story and Jira Support synchronize to an ALM Octane story.
Field mappings
The field mappings for this example are:
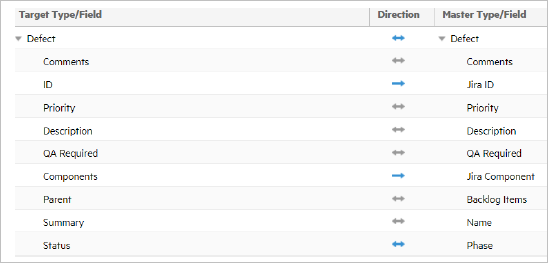
- The Jira key syncs uni-directionally to the ALM Octane Jira ID custom field.
- Jira Comments synchronize bi-directionally to/from ALM Octane Comments.
- Jira Defect Parent (Story) and ALM Octane Backlog Items synchronize bi-directionally.
The following example shows an ALM Octane and ALM/QC connection that synchronizes three ALM Octane workspaces to one ALM/QC project:
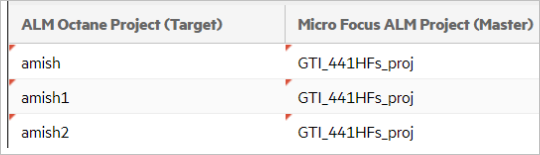
Field mappings
The field mappings for this example are:
- The Jira Story and Support types are mapped to the ALM Octane user story.
- The connection maps two Jira projects to an ALM Octane workspace.
-
Two user defined fields (UDFs) are defined in ALM Octane:
- jira_project_key_udf - String (label: Jira project key)
- Is_jira_support_udf – Boolean (label: Story is Jira support)
Master Sync Criteria
The following table shows the master synchronization criteria for several syncsets:
When syncing two or more projects (/workspaces) on one side to/from a single project on the other, or when syncing two or more types on one side to/from a single type on the other, use synchronization criteria with a custom field value to ensure that only relevant artifacts are loaded into each syncset. In this use case, do not specify Common Projects. For details, see Common projects vs. type-specific project maps.
| Syncset | Master Criteria |
|---|---|
| Story, DCRE |

|
| Support, DCRE |
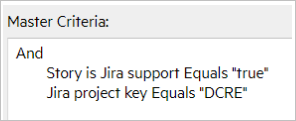
|
| Support, CLDXC |
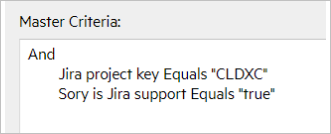
|
Master calculated values
The following table shows the master calculated values for the syncsets:
| Syncset | Master Calculated Value |
|---|---|
| Story, DCRE |
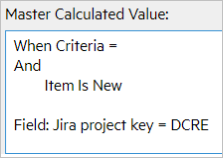
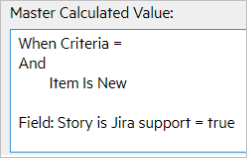
|
| Support, CLENT |
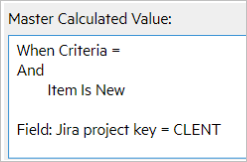
|
 Next steps:
Next steps:



