
Share this page





Troubleshooting
In Micro Focus Connect there are three main areas to review when a problem occurs during a connection run. In the UI you can refer to the Connection messages and Audit sections. The log files provide additional details. For details, see Gather debug information.
Connection messages
Connection messages provide:
- High level details about the Connection run. For example, the details include where the connection is within an iteration cycle, how many items are visible, and what actions were taken..
-
General errors encountered during the run. For example, an inability to connect to data sources or failure to access a project. You can find details of the problem in the Connect.log and Connect-Err.log files. Depending on the type of error, it may result in the Connection stopping. If you enabled email notifications, you will also receive an email regarding these errors.

Audit tab
The Audit tab provides additional insight into items that were created or updated during a Connection run.
Select a Connection, and click the Audit tab.
To display audit information:
-
Define a filter of the information you want to display in the left pane.
To focus on failed actions, in the Operation Type filter, select Failed Action.
- Click Run. The most recent activity of the Connection is displayed, broken down by iteration, project, operation type, item type, and item.
If an error occurred, the information includes the failure cause, and the failure stack trace with more details (when trace level is enabled). In most cases, these messages are the error that is returned by the product in the connection, for example, Jira or ALM Octane.
Note: If you purge the database at regular intervals, the Audit tab only shows the data since the last purge. Older audit data is exported into a file by the Purge scripts, and saved in the backup folder.
Common issues
The following section lists some issues that you may encounter.
Cause: This usually occurs if you have not mapped all list values for a field, or if you add new enumerated values after creating and running a connection.
Solution: Update and include additional values in the mapping.
- If you have added a new list value, click on the gear in the top right of the window and select Flush Server Cache
- Edit the Connection and the value mapping for the field.
Cause: Each product has its own representation of users, and may have multiple ways to represent users.
Solution:
- If you have consistent representations in the products you are using in a Connection, you can choose that representation for the users. You do not have to add users maps.
- If there are inconsistencies, or there are not equivalent representations, you need to add user maps.
Cause: If a project, type, field or field value has not been discovered by Micro Focus Connect, there are a few things you should consider:
Solution 1: Check if the user in the data source has sufficient privileges? Change the privileges as required.
Solution: 2 If the missing entity was added recently, follow these steps to make it visible to Micro Focus Connect:
- Click on the gear button in the top right of the window and select Flush Server Cache.
- Edit the connection by clicking the gear button adjacent to connection name and clicking Edit.
-
If the missing entity is a type, add the type to the data source:
- In the Data Sources tab, click Reload.
- Select the data source, open the Types tab, and add the type.
- Open the Relationships tab and click Apply Default Model. Micro Focus Connect checks if the new type is related to any other types.
Cause: This is most likely an item dependency issue. If you are running a Run One Iteration of items that depend on other items, for example syncing tasks and stories, it is possible that tasks are initially synced, and therefore be unable to find their story.
Solution: The first iteration adds the story, after the task. One a Run One Iteration a second time. The tasks are then linked to the story. If there are chained relationships, you may need to run it multiple times.
Cause: Does your Jira board include everything, or is filtered?
Solution:
- Check the Board in Jira, and see if the item in question is visible.
- Review the Board settings to make sure the query is correct and all Status values are present.
Cause: The metadata for each of the projects is different. Therefore the projects cannot be synchronized in the same connection, or if they are based on the same data source. (In at least one of the projects, possibly both, the data source sample project schema will differ from one or the other or both.)
Solution: The project-specific metadata schema has to be identical for all participating projects (workspaces) of a selected endpoint. Modify the metadata so that they match by defining all of the metadata in the template project. Then inherit projects from the template project, without changing the child project's schema. These requirements are true for every endpoint system that needs to be synchronized, specifically in a single-connection, multi-project scenario.
Cause: You may have recently restarted the Micro Focus Connect service and the connection details have not loaded.
Solution: After restarting the Micro Focus Connect service, if a connection does not open, try again after a few seconds.
Cause: Micro Focus Connect cannot create new items in a data source if the user, whose credentials are used to define the data source, does not have sufficient permissions to create those items.
Solution: Check the permissions in the data source. Make sure the connecting user has Create permissions for the data type that is being synchronized.
Cause: The sample workspace may not have the same Application Module names.
Solution: Make sure that the sample workspace uses the same Application Module names. This is necessary to be able to find the appropriate module.
Solution: Make sure Elasticsearch is running.
Database issues
The following section lists an issue that you may encounter with the Micro Focus Connect database.
Issue: A 500 error is issued in the browser, upon the startup of Micro Focus Connect.
Solution: Follow these steps:
-
On the Micro Focus Connect server machine, stop the Micro Focus Connect service.
-
Open the error log and search for the following: org.apache.derby.iapi.error.StandardException: Recovery failed unexpected problem: Log record is Not first but transaction is not in transaction table :. If this message is present, the error is most probably due to the recovery mechanism.
-
Navigate to the installation folder..\Connect\AppData\data\db\log and delete its contents.
-
Check that you have enough disk space on the Micro Focus Connect machine. If necessary, free up or allocate additional disk space,
-
Restart the Micro Focus Connect service, and verify that you can log in successfully.
Issues with synchronizing ALM/QC projects
This section describes common issues that you may encounter when syncing ALM/QC projects.
This section describes an exception that you may have received when mapping an ALM/QC User field to a User field on the other endpoint. A common exception is:
com.connect.api.exceptions.BCException: cannot translate fromField={"SyncableField":{"fieldName":"owner","fieldLabel":"Affected By","fieldType":"FIELD_TYPE_ENUM","fieldUnits":"UNITS_NONE","fieldRequired":"IS_NOT_REQUIRED","isReadOnly":false,"isMultiValued":false,"isParentField":false,"isHtml":false,"isUserField":false,"uniqueField":false,"isLinkField":false,"referredToLinks":[],"connectorFieldInfo":""}} to {"SyncableField":{"fieldName":"owner","fieldLabel":"Affected","fieldType":"FIELD_TYPE_USER","fieldUnits":"UNITS_NONE","fieldRequired":"IS_NOT_REQUIRED","isReadOnly":false,"isMultiValued":false,"isParentField":false,"isHtml":false,"isUserField":true,"uniqueField":false,"isLinkField":false,"referredToLinks":[],"connectorFieldInfo":""}}
at com.connect.server.sync.field.FieldTranslator.translateFromEnumField(FieldTranslator.java:471)
...
Issue: The most probably cause is that the ALM/QC project metadata (for this connection) for the Affected by field, understands that the field is an Enum List.
To verify that this is a metadata issue, run this query in ALM:
Run this REST query in ALM.
https://{almserver:port}>/qcbin/rest/domains/{domainName}/projects/{projectName}/customization/entities/{typeName}/fields?login-form-required=y
If the query returns this type of response, it indicates that ALM/QC believes that the detected-by User list is an Enum list with a list_id of 1234.:
<Field PhysicalName="BG_DETECTED_BY" Name="detected-by" Label="Detected By">
<Size>60</Size>
<History>false</History>
<List-Id>1234</List-Id>
<Required>true</Required>
<System>true</System>
<Type>UsersList</Type>
<isTime>false</isTime>
…
</Field>
Solution: The resolution involves identifying the field which is corrupted and fixing it using an SQL DDL statement with the following syntax:
UPDATE SYSTEM_FIELD set sf_root_id=null where SF_COLUMN_NAME='FIELD_NAME'
UPDATE SEQUENCES SET SQ_SEQ_VALUE = SQ_SEQ_VALUE + 1 WHERE SQ_SEQ_NAME IN ('SYSTEM_FIELD','FIELDS_VERSION')
To run these queries, contact support.
If multiple ALM/QC projects use UDFs (user-defined fields) with the same name but different labels, the synchronization may fail to get the right field values.
The following example shows a uni-directional synchronization between Azure DevOps user stories to ALM requirements, where Azure DevOps, the parent, is mapped to the custom UDF in ALM/QC, AzureID.
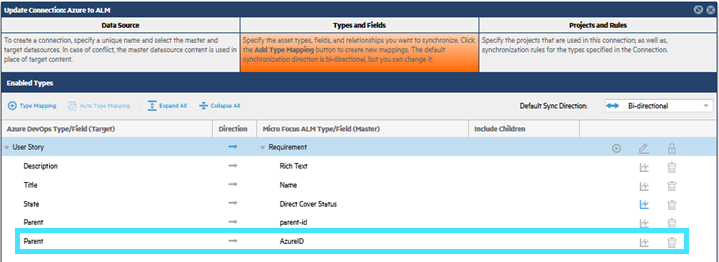
In ALM/QC the AzureID is empty.
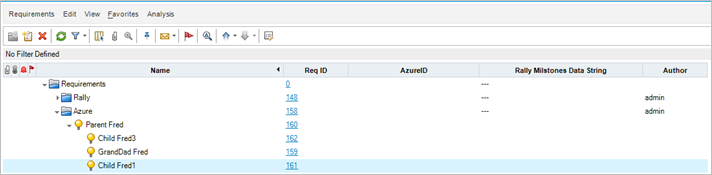
After clearing the watermarks and running one iteration on the connection, the audit states that the AzureID UDFs have been updated.
In ALM/QC however, the AzureID UDF was not updated, but a different UDF, Rally Milestones Data String, was updated.
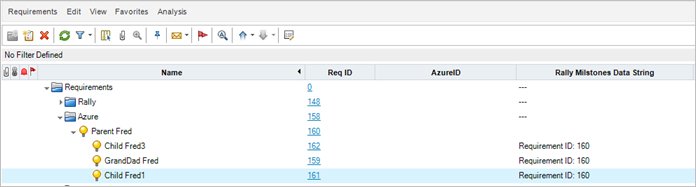
Cause: The cause for this issue is the sample project in the data source. The AzureID UDF has the name RQ_USER_09 (user-09). In the project defined in the connection, the Rally Milestones Data String UDF is also named RQ_USER_09 (user-09).
Sample project user-defined fields as defined in the data source
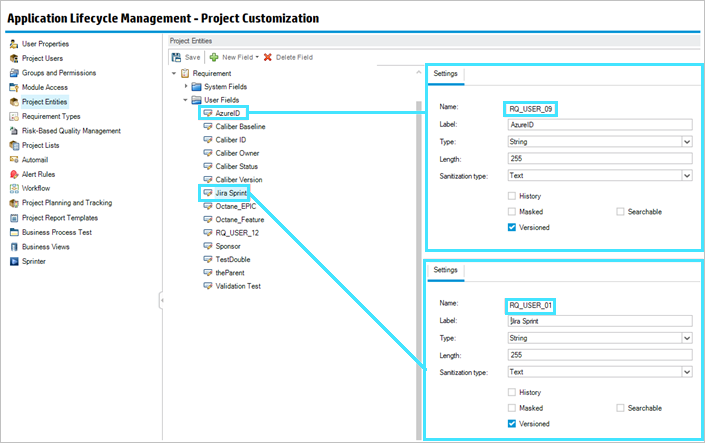
Master ALM/QC project user-defined fields as defined in the connection
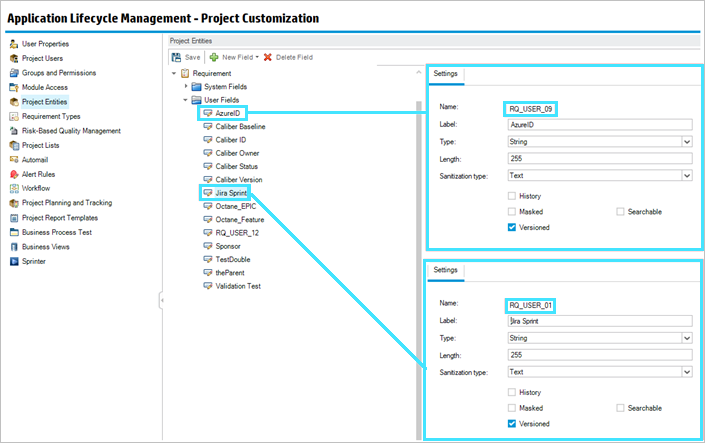
Solution: Always use a template project as the ALM/QC data source project, and ensure that the projects synchronizing on the connections use that template. For details, see Data source settings.
If this is not possible, create a separate data source for each connection.
Support requests
To facilitate the routing of Micro Focus Connect support requests, follow these guidelines:
-
SaaS. If the OpenText product you are trying to synchronize using Micro Focus Connect is deployed as a SaaS service, go to the SaaS My Account site and click the Support tab. Add "Connect" to the title and description.
-
On-premises. If the OpenText product you are trying to synchronize using Micro Focus Connect is deployed on-premises, go to the Support site and select the product under support—not Connect. Choose "Connect" as the sub-product. We recommend that you also add "Micro Focus Connect" as a prefix for the case title and to the top of the case description.
For initial assistance with Micro Focus Connect or the ValueEdge Integration Hub, contact the on-boarding team at DL-Connect-OnBoarding@microfocus.com.
 See also:
See also:



