
Share this page





Create a data source
This topic describes how to create a data source. A data source defines the attributes of a product (endpoint) that is part of a synchronization. Later, you create a connection that synchronizes between two data sources.
Note: If you are synchronizing with Jira, make sure your project is set up for synchronization. For details, see Prepare Jira for synchronization.
Access rights
When creating and using data sources, you need to make sure that Micro Focus Connect has access to the data source through an existing user account. For data source user accounts connecting to Jira, ServiceNow, ALM Octane, and ALM/QC, we recommend a service account with full administrative privileges—not a personal user account.
If you set the data source user account with non-administrator privileges, you must explicitly identify the minimal privileges required for the endpoints to successfully synchronize. If your synchronization fails, the cause may be insufficient privileges.
For example, your minimal permissions may exclude Jira query project lists, or ServiceNow query incidents, which would fail the synchronization. You need to add those privileges to enable a successful synchronization.
The access rights requirements described here are only relevant to the user account configured on the data source. They are not related to Micro Focus Connect users, or to users specified in user maps.

Default projects
The majority of data sources require you to specify a default sample project (/workspace) to be used as a template when you create a data source. Micro Focus Connect uses this project to discover the available types, fields, and list values that are available for configuring a connection based on this data source. This is required for products whose schema is customizable on a per-project basis, such as ALM Octane, ALM/QC, JIRA, Azure DevOps, Broadcom Rally, CollabNet Version One, and ServiceNow.
Make sure to specify a project that has all the entities you want to apply to the associated connections. It does not have to be the project whose data is being synchronized.
The metadata of the projects being mapped in the connection, must be identical to the metadata of the default project. For example, a project being synchronized on a given connection using a Jira data source, must have matching types, properties, and enumerated lists with the default project. However, the connection project does not need to be synchronized with the default project.
Certain product endpoints such as StarTeam, do not surface types, properties, list values, or users per project. Rather, they surface the same schema for the whole system. As a result , a default project is not required.
Data source settings
For any given data source, specify a sample project that includes all the entities required to be used within a connection and all the projects that the connection synchronizes. This serves as a template project.
Per project, check that all custom properties being mapped are of the same type, same name, and same label. This is true for the sample project and the project(s) being synchronized by the connection.
If one or more projects are expected to use a property whose schema is described by a different sample project, then that property must be the same as the one described by the sample project. Synchronization failures may occur if the properties do no match.
There are two main ways to create a single shared data source:
- across multiple connections
- as a single connection with multiple projects
Note: If you are configuring a shared data source as a single connection with multiple projects, the sample project schema (specifically for types and properties being synchronized) must be identical to all the constituent projects across the related connections.
You can create multiple data sources to the same product endpoint. In such configurations, assign each data source its own sample project.
For connections that synchronization only one endpoint, set a unique and separate data source for the master and for the target. The data source sample project should be set to the same project synchronized by the connection.
Define a data source
This section describes how to define a new data source.
To define a data source:
- Click the Data Sources tab.
- Above the Data Sources list, click + Data Source.
-
In the dialog box that opens, provide the following information:
New Data Source Name Enter a unique name for your data source.
We recommend not using whitespaces in the data source name. If you do need to use whitespaces, enclose the entire name with double quotes.
Data Source Product The products that are available in the list are the connectors that were added with the product installation or the ones that you downloaded from our community and installed yourself. -
Your data source is added to the list of data sources.
- Select your data source to edit its details.
-
Click the Properties tab. The Properties pane lists additional fields that are specific to the product.
 URL formats
URL formats
The following table lists the typical URL formats for common data source types. Replace the placeholders, <hostname> and <instance> with your actual server host name (for on-premises installations) or instance (for cloud implementations). Replace <port> with the port number, usually 8080, upon which the endpoint listens for its connections. Do not include the angle brackets.
Data Source URL format ALM Octane server URL -
On-premises: http://<hostname>:<port>
-
Cloud: https://<instance>.saas.microfocus.com
Azure DevOps URL -
On-premises: http://<hostname>:<port>/DefaultCollection
-
Cloud: https://dev.azure.com:<instance>/DefaultCollection
Jira URL -
On-premises: http://<hostname>:<port>
-
Cloud: https://<instance>.atlassian.net
ALM/QC server URL <hostname> (without http) Rally URL https://rally1.rallydev.com ServiceNow server URL <instance>.servicenow.com (without http) VersionOne URL https://www16.v1host.com/<instance>/ For additional information about the properties, click View Readme. The readme file that was installed with your connector is displayed in the lower pane.
-
Guidelines for working with data sources
This section lists several guidelines that apply to Micro Focus Connect data sources.
- The bottom pane displays a Type with the name ChangeSet. You do not need to make any changes within this pane.
- You can delete a data source provided that it is not included in a connection. Once a data source is included in one or more connections it cannot be deleted. To delete a data source, you must first delete all connections associated with the data source. For details, see Connection scripts.
- You can use the same data sources in multiple connections. Data sources describe how to connect to a server. The connection then uses the data source to describe how to map types and projects within that data source.
- You cannot use the same data source for both sides of the connection. If you want to synchronize between projects within the same product, you can create a second data source with the same server details, and use the two data sources at either side of a connection.
- After you create a connection, you can specify any number of combinations of projects between the data sources. The only condition is that the paired projects need to conform to the data source restrictions. For example, Azure DevOps, the paired projects must be of the same type.
Tables to include in a ServiceNow data source
This section describes how to determine which table to include in a ServiceNow data source.
You can customize ServiceNow types to inherit all fields from a parent type. When you set this property, the data source is required in order to access referenced types. This section describes how to determine the source types for all fields and how to include them in your data source.
To determine the required data source types:
-
Create a ServiceNow data source.
-
Navigate to the Utilities folder of your Micro Focus Connect installation folder, by default C:\Program Files\Connect\Utilities. Open the mfcQueryTemplates.bat file in a text editor. For details, see QueryTemplates.
-
Edit the fields in bold. The USER and PASSWORD are the ones used for Micro Focus Connect. The DATA_SOURCE is the name of the ServiceNow data source that you created, and the TYPE is a type to be synchronized. PROPERTY is optional. For example:
set USER=admin
set PASSWORD=my_password
set HOST=localhost
set PORT=8081
set DATA_SOURCE=MFServiceNow
set TYPE=rm_story
set PROPERTY=propertyName -
Open a command prompt as Administrator and navigate to the Micro Focus Connect Utilities folder. Run the mfcQueryTemplates script. The script creates the following files in the Utilities folder:
-
<data_source_name>.txt
-
<data_source_name>.rm_story.txt
-
<data_source_name>.rm_story.propertyName.txt
-
-
Open <data_source_name>.txt in a text editor.
-
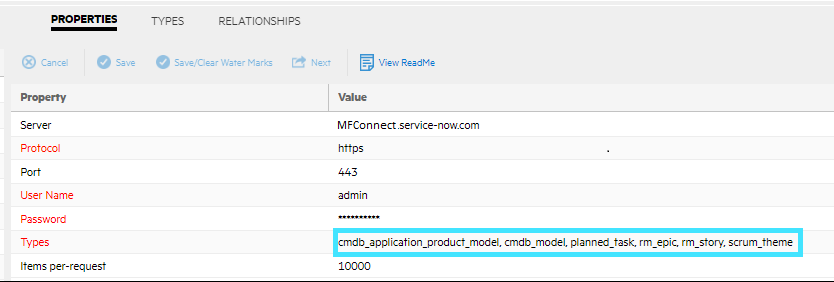
Search for the string referredToType and save the list of values. You will receive results beginning with the type name. In the above example, the search returns the following tables: rm_story, rm_feature, rm_epic, planned_task, cmdb_model, rm_enhancement, rm_sprint, rm_defect, scrum_theme, and rm_release_scrum.
-
Repeat the above steps for each type that you are synchronizing. Add any additional tables to the above list.
-
Copy the comma-separated list and paste it into the data source. Save the data source.
 ;
;
Swap the master and target data sources
Once you select a master and target for a connection, you cannot change them. You can create a different connection, provided that the master is a Micro Focus product, as the term master only applies to Micro Focus products, such as ALM Octane and ALM/QC. The term target applies to all products, for example Jira, ALM/QC, ALM Octane, and Azure DevOps.
You can however, change the direction of the data flow in the following way:
- If you want data to flow from Jira to ALM Octane, set the direction to To Master.
- If you want data to flow from ALM Octane to Jira, set the direction to From Master.
- If you want data to flow in both directions, select Bi-directional.
This does not impact cross references, since they remain unchanged inside the Micro Focus Connect database.
 Next steps:
Next steps:



