
Share this page





Data Driving
To facilitate data-driven testing, you can add external data sources to your virtual services. Service Virtualization now supports file-based (Microsoft Excel or CSV) or a relational database (Microsoft SQL Server, Oracle, PostgreSQL) data source.
When you associate an external data source with a virtual service, you need to create mappings between the columns in the external data source, and the columns/headers in your data rule. You do this by configuring the binding in the Data model.
Array Binding
You can also bind array data. When the message structure contains an array that needs to be data-driven, you need to work with a properly structured data source.
In case of an Excel file, it must contain database-like relationships, using primary and foreign keys, which allow the mapping of one row to many. You can create the file manually, or export learned data in the desired format, to a new Excel file.
In case of a database data source, OpenText Service Virtualization can detect the existing database relations and suggest them when binding the array rows.
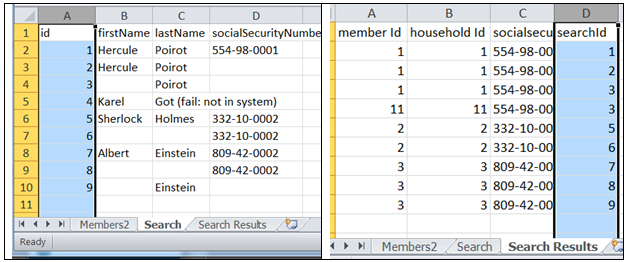
The following example shows the relationship between a search definition and the search result. A record in the Search worksheet is identified via its primary key ‘id’, and referenced from the Search Result worksheet via the foreign key ‘searchId’. This enables the return of two rows for a search with id 3, or zero rows for search of id 4.

Data Format Binding
When binding to a data source column where the response can contain different data formats (such as for the REST protocol), different response types (such as for the SOAP protocol), or a message structure which can be considered to contain different types, you can also configure binding for this in your data model.
You can configure mappings between real types or formats and data source values, and provide a default value that is used when no value from the mapping table matches. You can configure a value for each possible type or format.
For task details, see Work With External Data Sources.
Limitations when working with CSV data source files
Note the following when using a CSV data source type:
-
You can only use an existing data source when creating the data driven rule; creating a new data source is not available for a CSV file.
-
CSV does not support arrays or relationships between tables, since there is just one table in CSV which is the CSV file content.
-
When creating a data driven rule for a CSV file, you have to specify the delimiter. By default, the delimiter is a comma (,).



