
Share this page





Use-case: Syncing ALM Octane and Jira
The following use-case illustrates how to set up a connection between ALM Octane and Jira.
Overview
This section provides an end-to-end flow for a synchronization between ALM Octane and Jira. Although your exact environment may require different configuration steps, we recommend that you review this use-case to get an idea of what the end-to-end workflow involves.
In this example, our development is managed in Jira, and our QA is managed in ALM Octane. This means that stories are created in Jira and synced to ALM Octane. QA tracks their testing in ALM Octane and pushes their results to Jira.
Caution: We do not recommend testing this procedure in a production environment. To learn the Micro Focus Connect workflow you can use a demo environment with demo data on both Jira and ALM Octane.
Benefits of Micro Focus Connect and the ALM Octane – Test Management for Jira plugin
The ALM Octane – Test Management for Jira plugin helps Jira users establish visibility into the quality process being managed in ALM Octane. For example, you can see the test coverage of an ALM Octane user story in Jira. For details, see ALM Octane – Test Management for Jira plugin.
With Micro Focus Connect you can synchronize entities and issue types between ALM Octane and Jira, including releases, sprints, and backlog items, but not including tests.
If you use both Micro Focus Connect and the ALM Octane – Test Management for Jira plugin, backlog items are synced from ALM Octane to Jira using Micro Focus Connect. For those backlog items you see test coverage in Jira using the plugin.
The plugin works based on a user-defined field that is created in ALM Octane that contains the Jira issue type key. This way the plugin knows where to put the test coverage details. Using Micro Focus Connect can make this easier by populating the ALM Octane UDF with Jira key values.
Data model normalization
When synchronizing between products that have different data models, such as ALM Octane and Jira, you need to plan for how to normalize those models.
For example, in a case where you want to synchronize sprints from Jira to ALM Octane. In Jira, sprints are not required to have start and end dates, and in many cases cannot have start and end dates until they are the active sprint. Additionally, in most versions of Jira, there is no way to relate sprints to versions/releases.
In ALM Octane, sprints must be related to a release, they must have start and end dates, the start and end dates must fit within the release with which they are associated, and they cannot move across releases. Therefore, if your use case is to define sprints in Jira and send them to ALM Octane, you will need to have a clearly defined approach indicating to Micro Focus Connect which ALM Octane release to associate with each Jira sprint, to ensure that they have correct start and end dates.
Alternatively, since Jira is less restrictive when creating sprints, synchronizing sprints from ALM Octane to Jira would require far less consideration as there are no default dependencies, date requirements, or release dependencies.

Prerequisites
-
On the ALM Octane side, you need to create an API key that has both workspace admin and space admin roles in the workspace you are synchronizing.
-
On the Jira side you need to have a project, and a board that includes everything in that project. This is required because Micro Focus Connect reads Jira content from the board.
-
You need to have installed the Jira connector, which is not downloaded as part of the default Micro Focus Connect package. The Jira connector can be downloaded from the Connectors Marketplace.
Step 1: Define the ALM Octane data source
In Micro Focus Connect, you first define an ALM Octane data source and a Jira data source. After each data source is defined, sample data is collected from each data source regarding their types, fields, and values.
-
In the Data Sources tab, click the + Data Source button, and specify a data source name and product (for example, Octane 1 and ALM Octane).
Note: Data sources and connections cannot be renamed, so be careful to use names that will be useful over time.
-
Type the ALM Octane server URL defined as http://<server>:<port>. Enter the client ID and secret from the API key you created earlier, and click Next.
-
Select a space, and click Next.

-
Select a workspace that has types, fields, and values similar to the data that you want to sync, and click Next.
(After setting up the connection you can synchronize with multiple workspaces in the selected space.)
-
Select a default release for sprints.
This is needed because in Jira sprints can be unrelated to releases, while ALM Octane always links sprints with releases. Any unrelated sprints from Jira are assigned to this default release in ALM Octane.
-
Click Save. A system check verifies that the values you have entered are valid.
On the Types tab, you can see the entities that were identified in the ALM Octane workspace as available for synchronization. On the Relationships tab, you can see the available relationships.
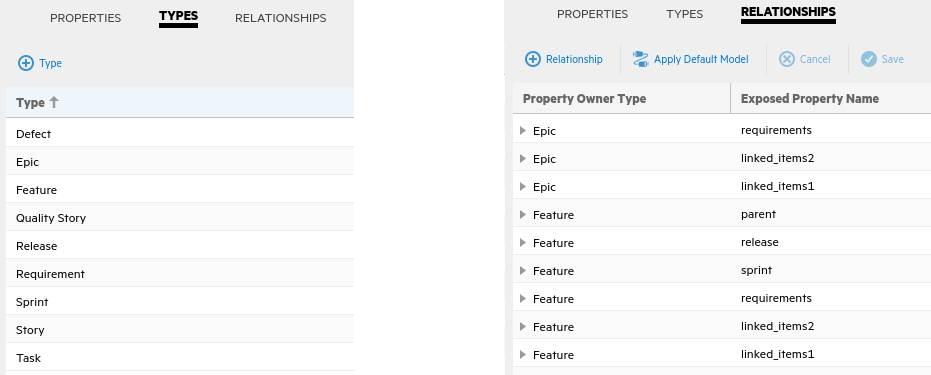
Step 2: Define the Jira data source
You now repeat the above steps to define the Jira data source.
-
Click the + Data Source button, and specify the Jira data source name and product (for example, Jira 1 and Jira).
-
Type the Jira server URL defined as http://<server>:<port>, and enter a user and password that has full read/write privileges for the Jira instance. (For Jira Cloud, enter a user and token.) Click Next.
- Note:
- If you receive a message indicating a problem with certificates, import your Jira certificate to the Micro Focus Connect web server to enable Micro Focus Connect to access Jira. For details, see SSL/TLS configuration.
- The Jira user account must use English UI settings (en-us or en-uk). In addition, if you are using the SAFe add-on for Jira, review locale information in Jira SAFe Plugin.
-
Select a project that has types, fields, and values similar to the data that you want to sync. Click Next.
-
Select a board for the project.
Tip: We recommend that you create a dedicated board for Micro Focus Connect showing everything in the project, rather than use an existing user board where you might change filters and block visibility to Micro Focus Connect .
Optional: In the Types field you can filter which types you want to sync for performance purposes. Click Next.
-
We recommend that you leave the remaining fields as set by default, and click Save. A system check verifies that the values you entered are valid.
On the Types tab, you can see the entities that were identified in the Jira project that are available for synchronization. If you have custom types that you want to add, click + Types and select the type you want to add.
On the Relationships tab, you can see the available relationships.
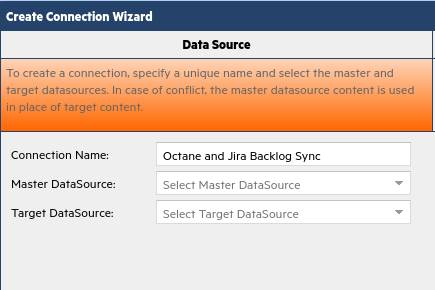
Step 3: Create Connection Wizard > Data Sources tab
You now create a connection between the two data sources using the Create Connection Wizard. First you specify the data sources:
-
In the Connections tab, click the + Connection button.
-
In the Data Source tab, name your connection (for example, Octane and Jira Backlog Sync).
-
Select ALM Octane as the master and Jira as the target data source. Leave the remaining settings as set by default, and click Next.
Step 4: Create Connection Wizard > Types and Fields tab
The wizard creates an initial auto-mapping of fields. You enhance the mappings in the Types and Fields tab.
Map between types and fields on both ends:
-
In the upper right, the Default Sync Direction is set to bi-directional. Do not change this default setting. This affects both creation and updates of entities and types. Instead this use-case modifies the direction at the type and field level.

-
This use-case creates stories in Jira and pushes them to ALM Octane. Set the story direction as Jira -> ALM Octane.
Click the pencil next to the Story type to edit its settings, and set the type's Direction as -> To Master. The direction set on the type is used for the creation of items, so when a story is created in Jira, it is pushed to ALM Octane (but not from ALM Octane to Jira).

-
In the lower pane you can see mapping between the fields, which impacts the direction of updates between the data sources. Although you are pushing stories from Jira to ALM Octane, you want to allow users in ALM Octane to update these fields and push updates to Jira, so you modify these fields to be bi-directional.
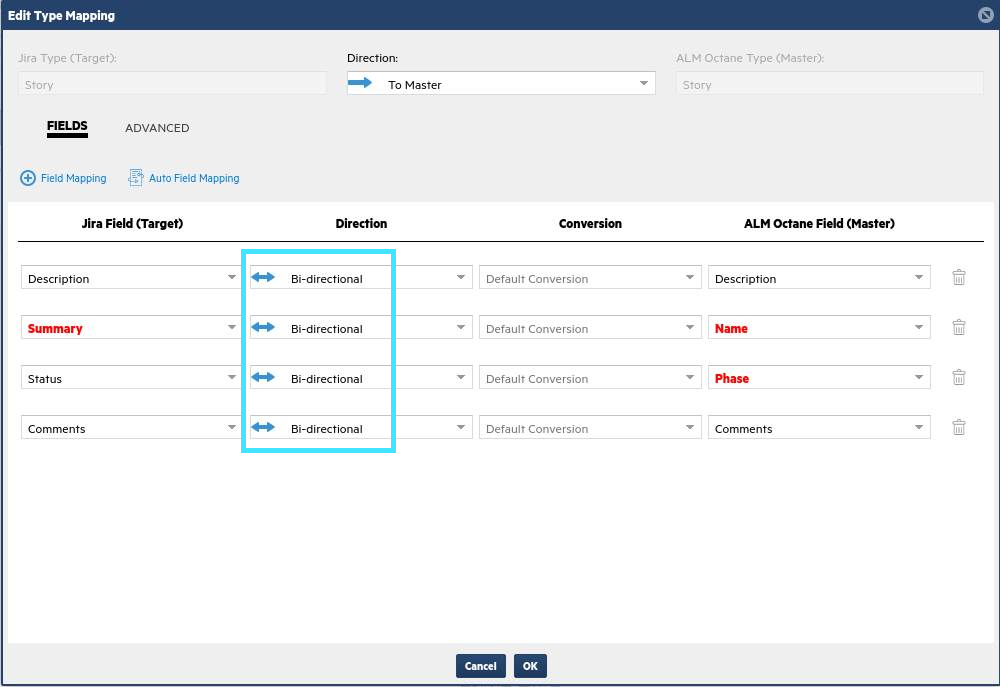
Note: You can click + Field Mapping to add other fields such as points, priority, and so on.
However, you cannot synchronize a link to an item before you sync the item itself. Therefore you will return to this section after you synchronize between the basic fields, and add link fields such as Epic link.
If you are not sure if a field is a link field, you can look at the Data Source > Relationships tab. If you see a field listed there, it is a link field, and you need to first sync the items before you can sync their links.
-
List fields typically need to be mapped. For example, statuses in Jira need to mapped with phases in ALM Octane because they are not automatically aligned with one another.
Click the Value Mapping button to the right of the Status and Phase row, and map each unmapped value.
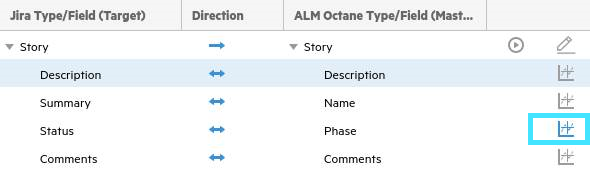
For example, if In Testing in ALM Octane is not mapped to a value in Jira, click Select a Value in the Jira column and choose the value In Progress.
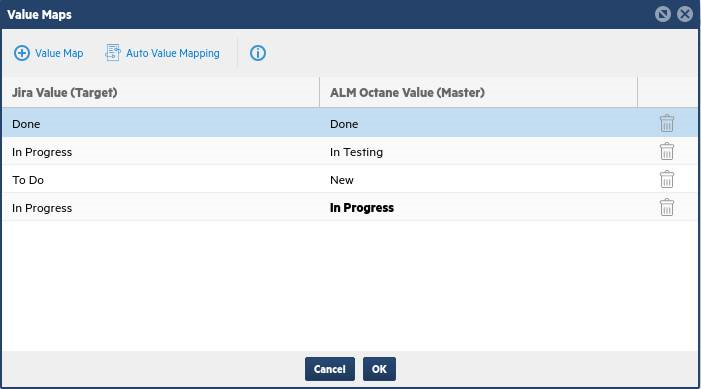
-
This use-case also synchronizes bugs with defects, but not tasks with sub-tasks. Therefore, you click Delete for the task and sub-task types (and their values).

-
Bugs and defects can originate in either system, so you can leave them as bi-drectional. Map the values from ALM Octane defects to Jira bugs as follows:
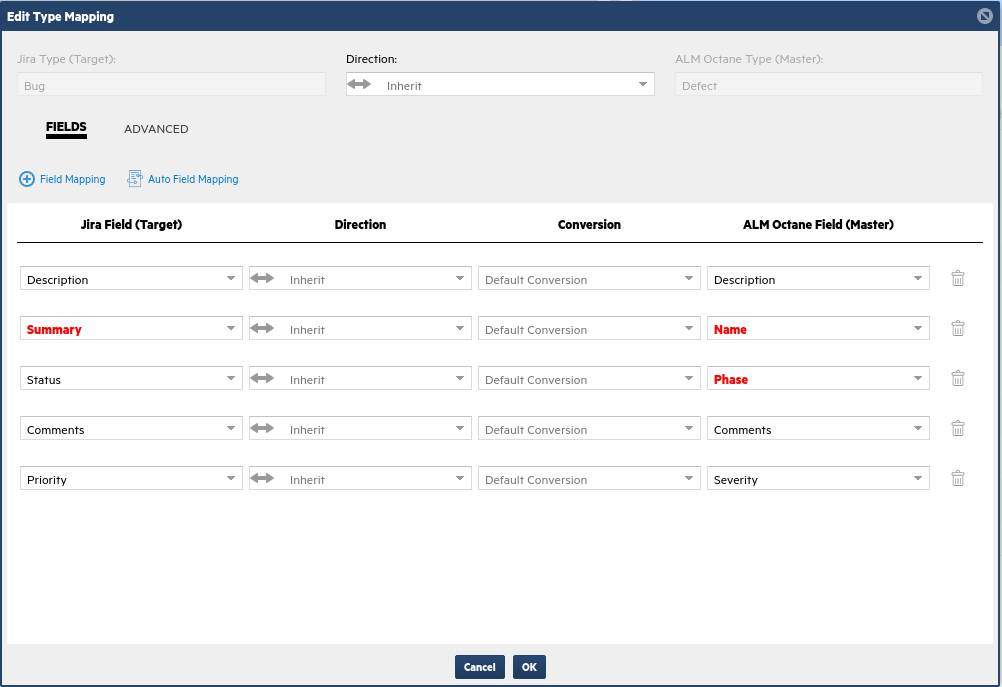
If a field is required in one of the sides, it is highlighted in red. Make sure to map any required fields that are not automatically populated.
Similar to the value maps you set for stories, you also need to set value maps for fields like Phase and Severity on Defects.
-
For this use case you want to add the Feature type, which exists in ALM Octane but not in Jira.
Click + Type Mapping, and select Epic on the Jira side, and Feature on the ALM Octane side. Set the direction from Jira -> ALM Octane (similar to stories).
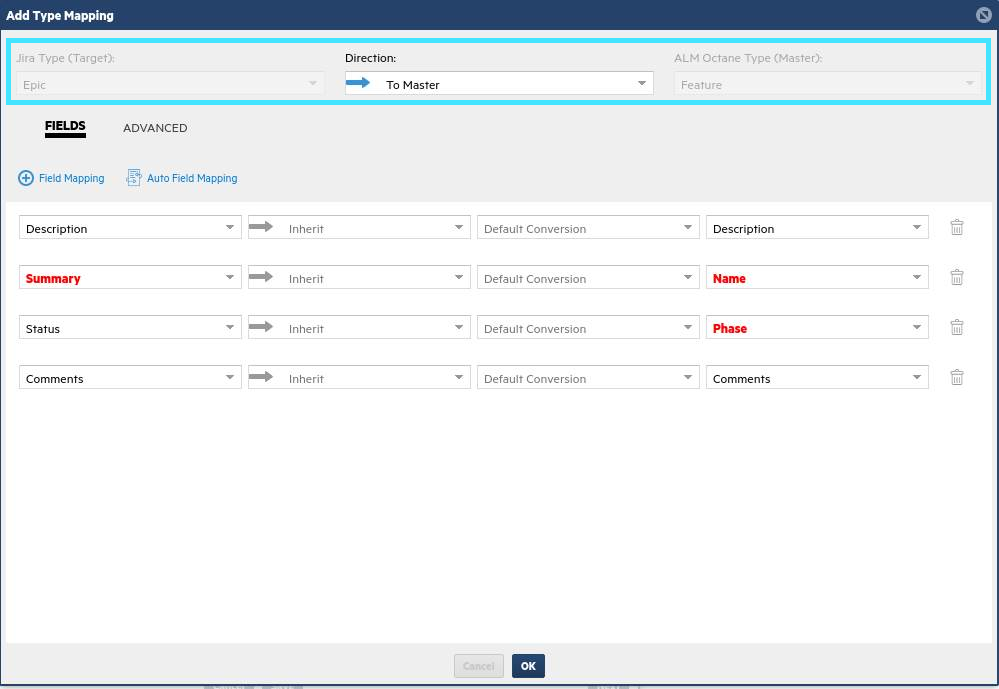
-
Click Auto Field Mapping to populate the field mapping quickly, then modify or add fields as described above.

Remember to also add value maps for fields such as Phase.
-
This use-case also adds releases and sprints using the above steps. Add each type, and map them as uni-directional from ALM Octane to Jira. (None of their fields need to be value-mapped.)
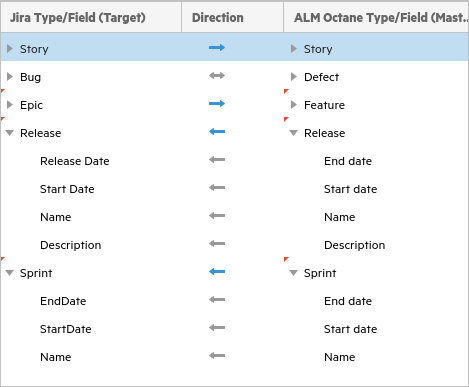
Alternatively, you can manually enter the sprint and release names in Jira and ALM Octane, and schedule runs of the matchByNameJiraOctane script to populate the cross references in the database. For details, see Batch utility scripts.
-
Click Next.
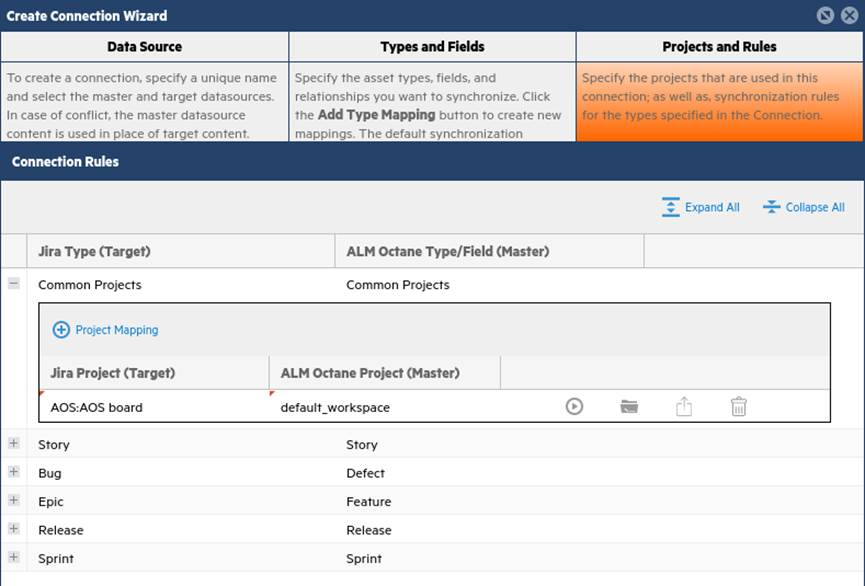
Step 5: Create Connection Wizard > Projects and Rules tab
In the Projects and Rules tab, you define which projects to sync. You can use the projects that you entered as the sample projects, or other projects.
-
If you map projects under the Common Projects heading, then all the types being synchronized are applied to the same two projects. In this use-case, stories, bugs, epics, releases, and sprints will all be synchronized in the two sample projects.
-
You could specify one project for stories and another for defects, or use different rules for different types (for example, only sync defects with a certain severity or priority). However, for simplicity, this use-case maps common projects.
-
At the very top under Common Projects, select the projects you want to connect. Do not set any projects under the individual types for this use case.
-
Click Save.
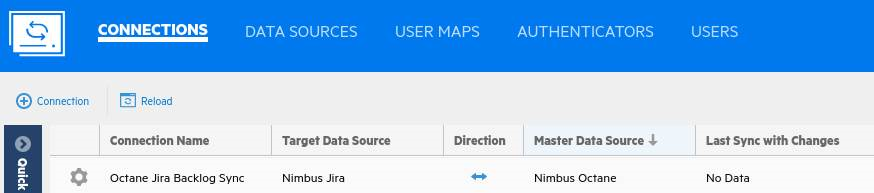
Step 6: Run one sync iteration in the Connections tab
At this stage, you synchronize to make sure everything is set up properly. We recommend that you first synchronize standalone types: stories, bugs, and epics. Then you can synchronize sprints and releases, which have dependencies. This makes it easier to debug any issues that may arise.
-
On the Connections tab, you can see the new connection.
Click the gear icon to the left of the connection name, and choose Run One Iteration.
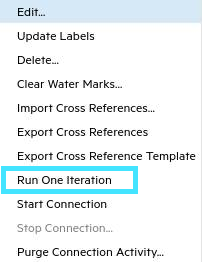
This runs one sync iteration, to test that it works properly.
Note: Running one iteration does not sync everything completely, especially if the sync was never run before, such as links between items or items that are in certain parent/child relationships.
-
Click the connection row. In the lower pane, open Connection Messages to track progress and look for errors. When the Status shows Disabled, the iteration is done.
-
In the Audit tab of the lower pane, click Run to run an audit. This gives you an idea of which types synced, and if there were any errors.
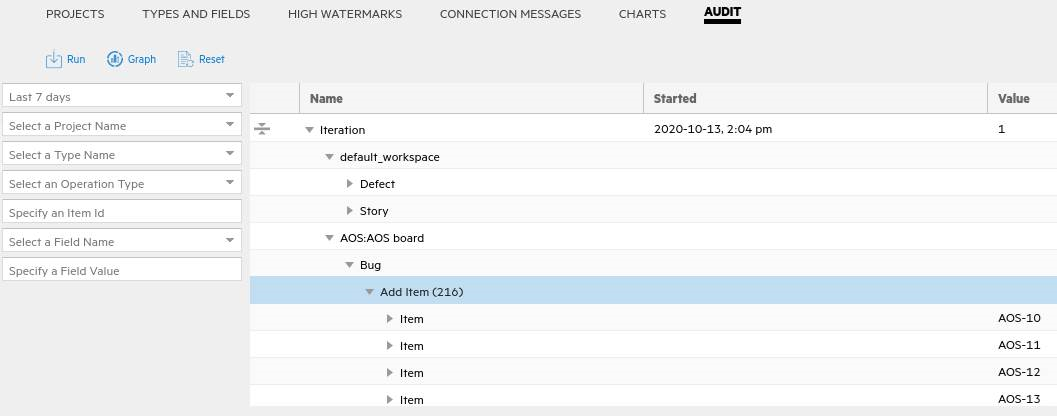
We recommend now looking at Jira and ALM Octane to verify that the expected items synced between them.
Step 7: Map relationship links
Now that you have synchronized epics, features, sprints, and releases, you can add their relevant relationship links.
-
In the Connections tab, edit the new connection.
-
In the Types and Fields tab, edit the Story type.
-
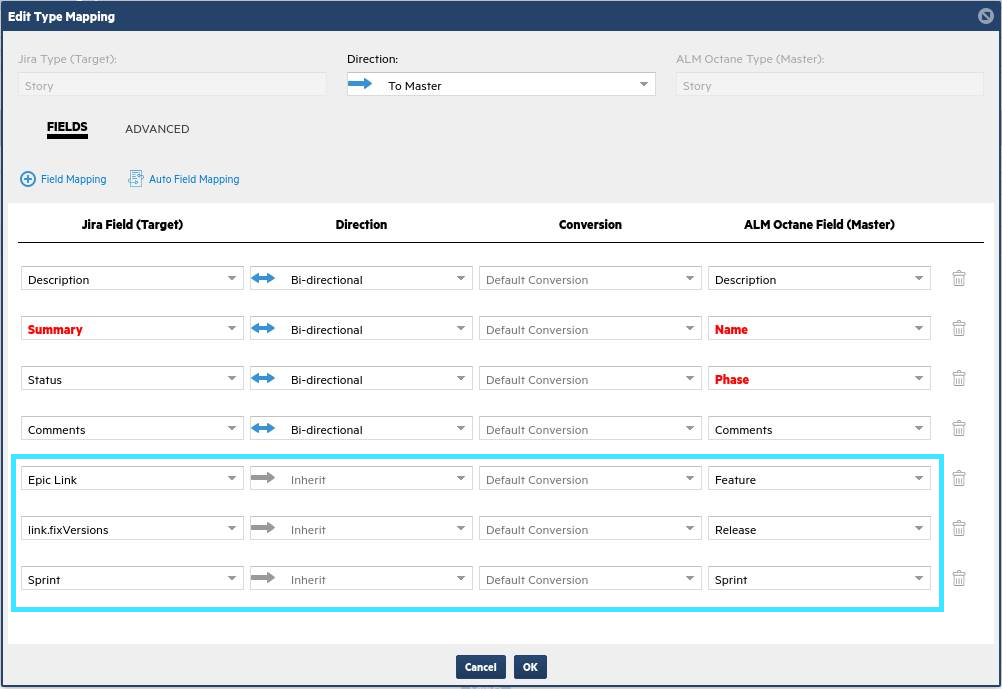
Add the following link mappings from Jira to ALM Octane:
-
Epic link > Feature
-
link.fixVersions > Release
-
Sprint > Sprint
These enable you to sync links between stories and their related features, releases, and sprints.
-
Step 8: Run synchronization
-
On the Connections tab, click the gear icon to the left of the connection name, and choose Run One Iteration to test the latest changes.
-
After the synchronization has been set up properly, choose Start Connection to run the synchronization continuously at the frequency defined for the connection.
Tip: For every iteration, a watermark is set so that the synchronization only looks for changes since the last iteration. If you run sync and do not see expected changes, this may be because you changed mappings since the last iteration, but the change is not registering because of an existing watermark. In this case, choose Clear Watermarks from the connection's gear icon before running sync.
 See also:
See also:



