
Share this page





Micro Focus Connect Basics
This topic provides an overview of Micro Focus Connect.
Micro Focus Connect concepts
Micro Focus Connect is a cross-product artifact synchronization engine that lets you synchronize data between two endpoints. It can create, update, and delete artifacts in a product, based on changes made in another product.
A connection contains two endpoints, Master and Target. Synchronizations are done between the master and the target. The Master must be a Micro Focus product, and the target can be any other another product, including other Micro Focus products. For a list of the supported products, see below.
Designating a project as a master or target does not indicate the direction of the data flow, as you can run uni-directional or bi-directional synchronizations. These synchronizations can be performed at the connection level, artifact type level, and field level.
Tip: If a change is made to both the master and target at the same moment, then a field value may become deadlocked. In this case, the master value is chosen to break the deadlock.
Micro Focus Connect uses a hub and spoke model. The hub is the Micro Focus product-agnostic service. Each target product is represented by a connector, a spoke.
Micro Focus Connect supports several types of mappings between masters and targets:
- One to one
- Many to one
- One to many
For a list of the supported connectors, see Supported endpoint connectors.

Planning guide and worksheet
Before you begin using Micro Focus Connect to synchronize your projects, it is essential that you consult the Micro Focus Connect planning guidelines. We strongly recommend that you start using Micro Focus Connect actively only after you have addressed the large majority of the questions and considerations discussed in the planning guidelines. This document provides you with important resources, checklists, and planning tables that you must be familiar with before creating connections.
Note: Smooth operation of Micro Focus Connect requires its administrator to understand how to work with common back end systems. For details, see Roles and responsibilities.
Data Sources
A Micro Focus Connect connection represents a synchronization between two data sources. The following table shows the relationship between the various elements.
| Element type | Is comprised of … |
|---|---|
| Connection | Data sources |
| Data source (end point instance of a product) | Types |
| Type | Fields |
| Relationships across Types | Links |
When synchronizing object hierarchies between products, a connection can use multiple types, including the relationships between objects and their parents. A connection can also include multiple projects. For example, a data source with one project, can synchronize to a data source with multiple projects, in both directions.
Each endpoint has a data source represented by a unique term with the following parameters:
- url | {protocol, host, port}
- user account | client id
- password | client secret | API key
- domain (for ALM/QC) | sharedspace (for Octane) | workspace (for Rally)
- A schema of the metadata for types and fields, in the form of a sample project.
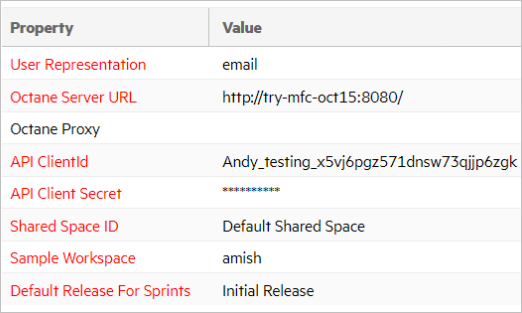
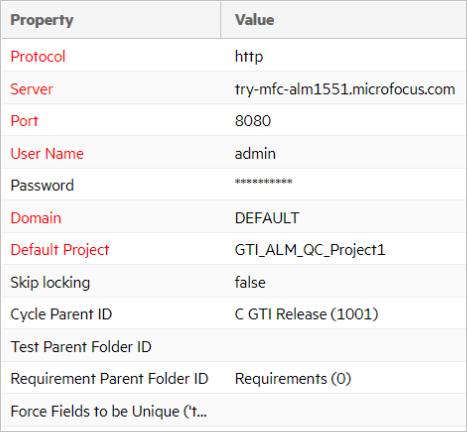
The following guidelines apply to data sources:
- Two ALM Octane shared spaces with the same URL, are considered different endpoints.
- Two ALM/QC domains at the same URL are considered different endpoints.
- Multiple connections to the same endpoint can share a data source.
For details, see Create a data source.
Connections
A connection represents a synchronization between two data sources (endpoints). Each connection is a collection of unique syncsets. A connection's syncset consists of a {Master Type, Target Type, Master Project, Target Project} pair.
The following guidelines apply to connections:
- Connections can be uni-directional or bi-directional
- Connections can contain one or more types, paired across endpoints. They can synchronize one to one, one to many, or many to one type mappings.
- Connections can contain one or more projects, paired across endpoints. They can synchronize one to one, one to many, or many to one Project mappings
- A pair of mapped types is comprised of a set of mapped fields. Field mappings may be uni-directional or bi-directional. Fields may be strings, numbers, booleans, lists, or references (links).
- By default, any non-string fields are automatically converted to strings. To convert to a specific type (for example, String to Number, String to Reference), use Calculated values.
- To limit the data included in the syncsets, use server filters and Sync Criteria. For details, see Add projects and rules to a connection.
Tip: In planning your synchronizations, we highly recommend that you run the Purge script as a nightly task. Failure to do so may cause the file folders to grow in size and overload the Micro Focus Connect memory. This also affects the Micro Focus Connect overall system performance. For details, see Purge scripts.
Value maps
A value map defines how a field value in Product A maps to a field value in Product B. If you mapped two select-list fields, you need to make sure that the fields' values are also mapped.
When mapping lists of values, the following guidelines apply:
- You can map the ALM Octane Phase to the ALM/QC Direct Cover Status.
- Each target entry must be mapped to an entry on the master.
- Unmapped entries trigger a synchronization failure on the artifact. For details, see FAQs.
The example below shows value mapping between ALM Octane and ALM QC projects.
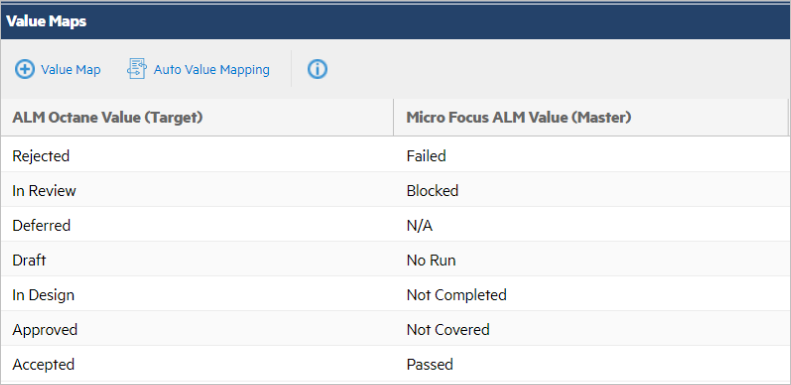
For details, see Create value maps.
Calculated values
Calculated values are field values that are automatically set during synchronization, when the specified conditions are met.
This example uses the FindFirst script to set a reference.
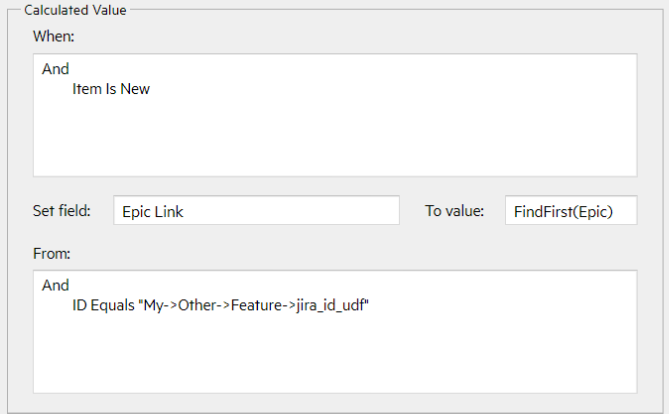
The example below de-references the ALM Octane parent story to set a Jira Bug text field to the parent’s name.
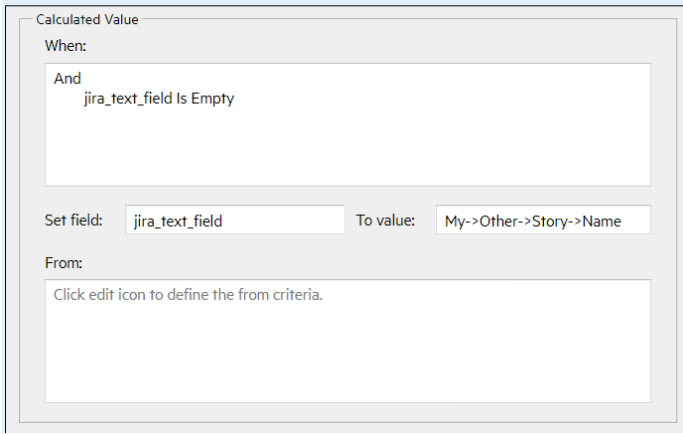
For details, see Define calculated values.
Sync Criteria
When working with large data sets on any given product, you need to determine which subsets to synchronize. This can be done using synchronization criteria.
You can set the synchronization criteria for your connections using logical statements. You can set criteria for both the master and target.
In this example, all defects created after 12/31/2020, whose status is either In Progress or To Do, are included in the synchronization:
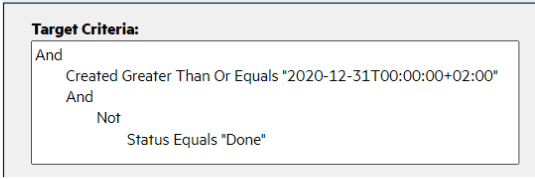
For details, see Define synchronization criteria.
Type and user maps
Before you run a synchronization, you must map fields between the data sources. Mappings in a connection are per project.
Type maps are the most convenient, and usually the most logical way to indicate corresponding fields between a master and target. The type in one data source synchronizes to an equivalent type in the other. For example, Micro Focus ALM Octane defects synchronize with Azure DevOps bugs. Micro Focus Connect does not dictate these type mappings. For complex use cases, you can choose to map completely different types across products, as long as the resultant data satisfies the product's workflow and integrity. The master and target Type mapping can be uni-directional or bi- directional.
User maps are user representations that map user properties across endpoints. You can manually construct the maps through the Micro Focus Connect user interface. User maps are ideal if you have different representations across endpoints. For example, when mapping between ALM Octane and Jira, the Jira assignee field needs to be mapped to the ALM Octane owner field.
The following are some common Micro Focus Connect user representations:
- Jira DisplayName
- Octane email, full_name or name
- ALM/QC loginname
- Azure DevOps DisplayName

Several batch scripts can be used in order to create user maps
- DataSourceUsers: Extracts all users directly from the data sources.
- UserMaps: Pairs and imports users into the Micro Focus Connect database.
For details, see Define user maps.
Audits
When a synchronization runs, it produces a report called an audit. Audit reports contain records of the items synchronized during an iteration, including successful operations (adds, updates) and failures, along with details and item counts.
Audit reports can be generated on-demand or scheduled as part of a nightly batch using the Audit batch script. For details, see Audit.
The following are some of the audit report features:
- Audit report outputs are generated in a CR/LF line separated format, “|” as a column delimiter, with a .txt extension.
- The output can be exported to a spreadsheet or any SQL database.
- If SMTP is configured, the audit can be emailed to server-wide recipients.
- Audit reports can be extracted for one or multiple connections.
-
If you purge the database at regular intervals, the Audit tab only shows the data since the last purge. Older audit data is exported into a file by the Purge scripts, and saved in the backup folder.
Tip: Make sure to purge the audit data on a regular basis. Failure to do so, may result in a disproportionately large AppData/data folder that retains all unpurged audit information in the Micro Focus Connect service memory. For details, see Purge files on Windows as a nightly task.
Sample audit report
The following example shows the information included in a typical audit report.
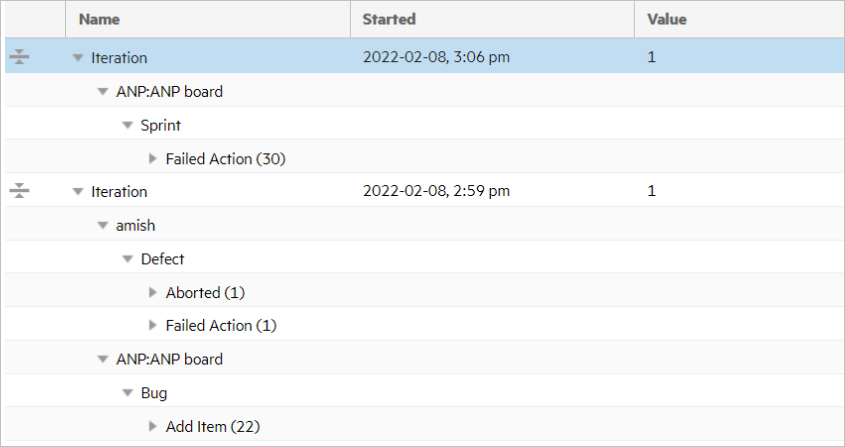
For details, see Audit tab.
Examples
The following examples illustrate the connections and mappings for several typical use cases. For details, see the Help Center's Methodology menu.
The following example shows an ALM Octane and JIRA connection that synchronizes five types:
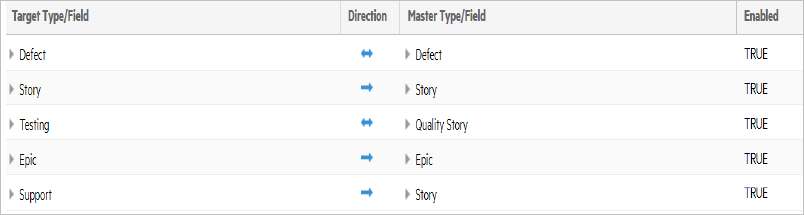
- A Jira defect synchronizes bi-directionally to an ALM Octane defect.
- A Jira epic synchronizes uni-directionally to the ALM Octane epic.
- Both Jira Story and Jira Support synchronize to an ALM Octane story.
Field mappings
The field mappings for this example are:
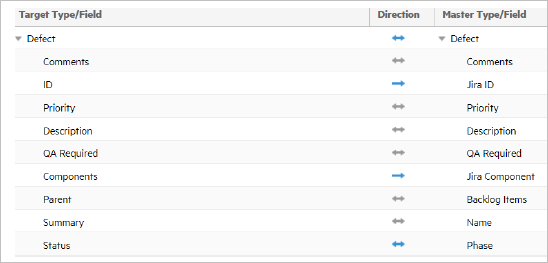
- The Jira key syncs uni-directionally to the ALM Octane Jira ID custom field.
- Jira Comments synchronize bi-directionally to/from ALM Octane Comments.
- Jira Defect Parent (Story) and ALM Octane Backlog Items synchronize bi-directionally.
The following example shows an ALM Octane and ALM/QC connection that synchronizes three ALM Octane workspaces to one ALM/QC project:
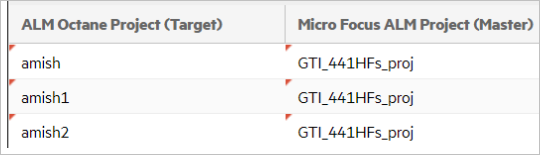
Field mappings
The field mappings for the this example are:
- The Jira Story and Support types are mapped to the ALM Octane user story.
- The connection maps two Jira projects to an ALM Octane workspace.
-
Two user defined fields (UDFs) are defined in ALM Octane:
- jira_project_key_udf - String (label: Jira project key)
- Is_jira_support_udf – Boolean (label: Story is Jira support)
Master Sync Criteria
The following table shows the master synchronization criteria for several syncsets:
When syncing two or more projects (/workspaces) on one side to/from a single project on the other, or when syncing two or more types on one side to/from a single type on the other, use synchronization criteria with a custom field value to ensure that only relevant artifacts are loaded into each syncset. In this use case, do not specify Common Projects. For details, see Common Projects vs. type specific project maps.
| Syncset | Master Criteria |
|---|---|
| Story, DCRE |

|
| Support, DCRE |
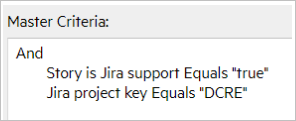
|
| Support, CLDXC |
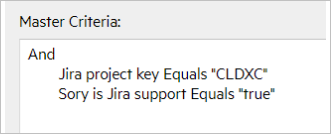
|
Master calculated values
The following table shows the master calculated values for the syncsets:
| Syncset | Master Calculated Value |
|---|---|
| Story, DCRE |
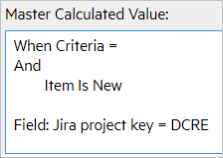
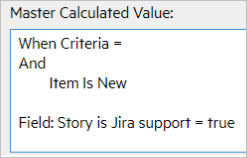
|
| Support, CLENT |
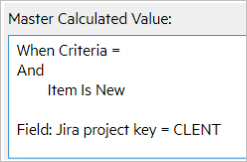
|



